Органы чувств в инфраструктуре
Вот упал у вас прод, вы заходите по ssh и видите, что Load Average в 10 раз больше, чем количество ядер. Люди не могут воспользоваться сервисом, партнёры задают вопросы, а всё, что вы знаете, — это то, что нагрузка выше номинальной. Где именно, из-за чего всё это случилось — непонятно.
Вы залезаете в консоль, ищете по логам (медленно, сервер-то перегружен), запускаете ps и strace, совершаете другие шаманские действия. Чувствуете, что двигаетесь по тёмному лесу с закрытыми глазами, как бегуны из старого клипа Pendulum.
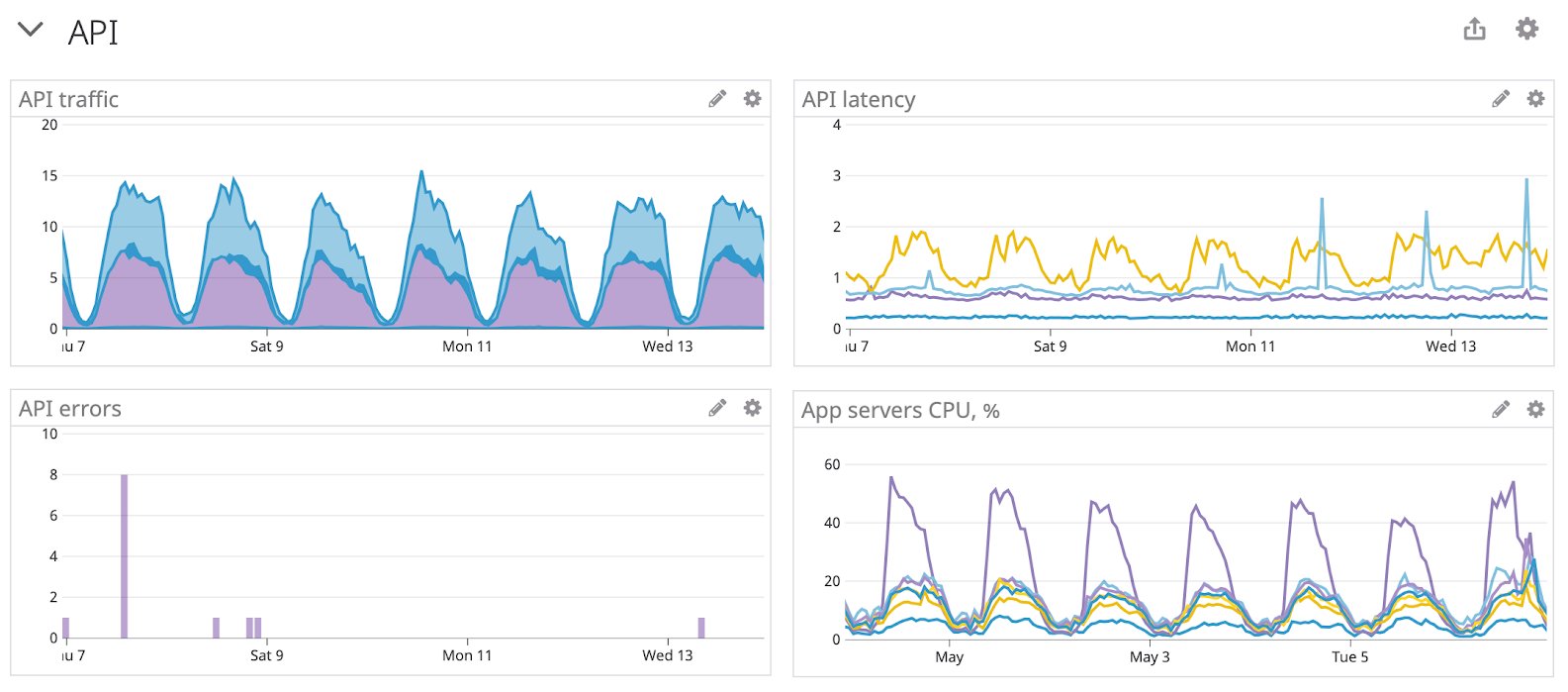
Выход простой — сделайте себе нормальные органы чувств. Заведите дашборды, которые покажут 4 золотых сигнала (время ответа, количество запросов, рейт ошибок и запас нагрузки) и ТОП-10 самых нагруженных эндпоинтов (отдельно по количетву запросов, отдельно — по затраченному машинному времени). 4 сигнала заменяют кучу производных метрик и позволяют однозначно сказать, лежит ли прод:
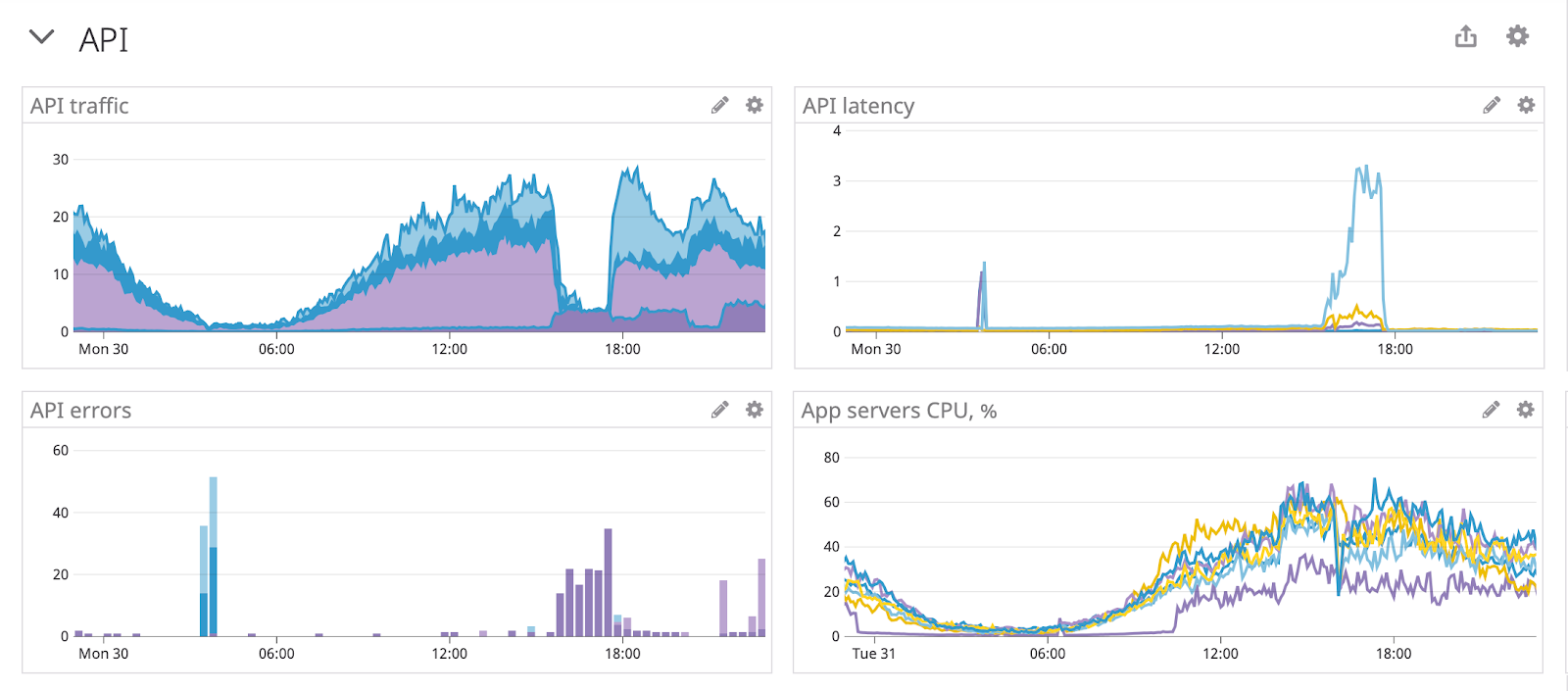
ТОП-10 запросов декомпозирует проблему из «упал прод» в «у нас тормозит эндпоинт деталей товара». Теперь легко локализовать источник — если увеличилось количество запросов, то ищем, того, кто их делает. Если запросов столько же, а нагрузка выросла — ищем, что поменялось в коде, или какие проблемы у нас могут быть на внешних ресурсах: базе данных, кеше или партнёрских API. Во втором случае здорово помогает разобрать поток выполнения — у каждого запроса, который обработал сервер, мы записываем трейс, в котором видно, сколько времени приложение потратило на каждую активность, а затем визуализируем это примерно вот так:
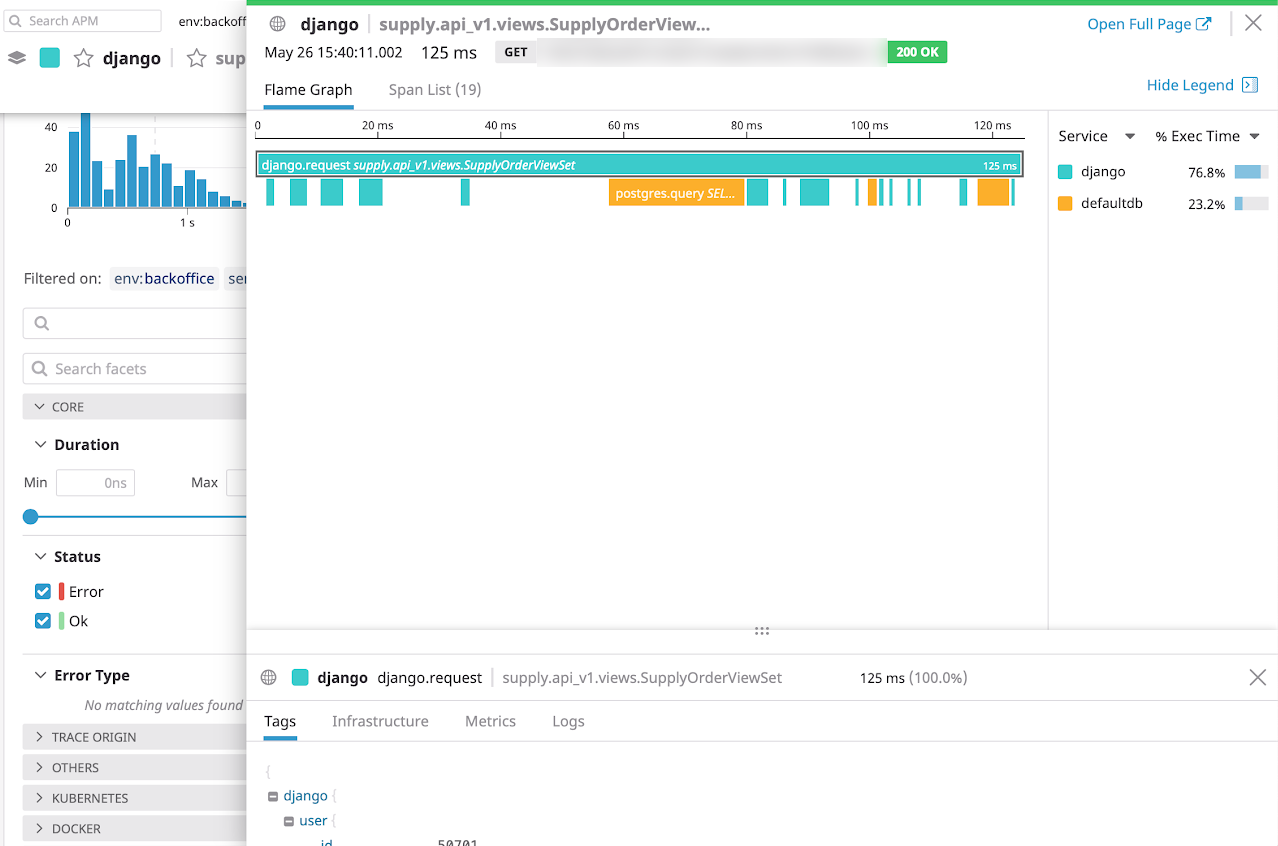
Такая работа с цифрами и статистикой называется APM — App Performance Management. Мой любимый сервис для APM — Datadog. Я выбрал его когда-то за хороший дизайн: Datadog не просто даёт инструменты, которые собирают цифры, но и подсвечивает и объясняет самые важные из них.
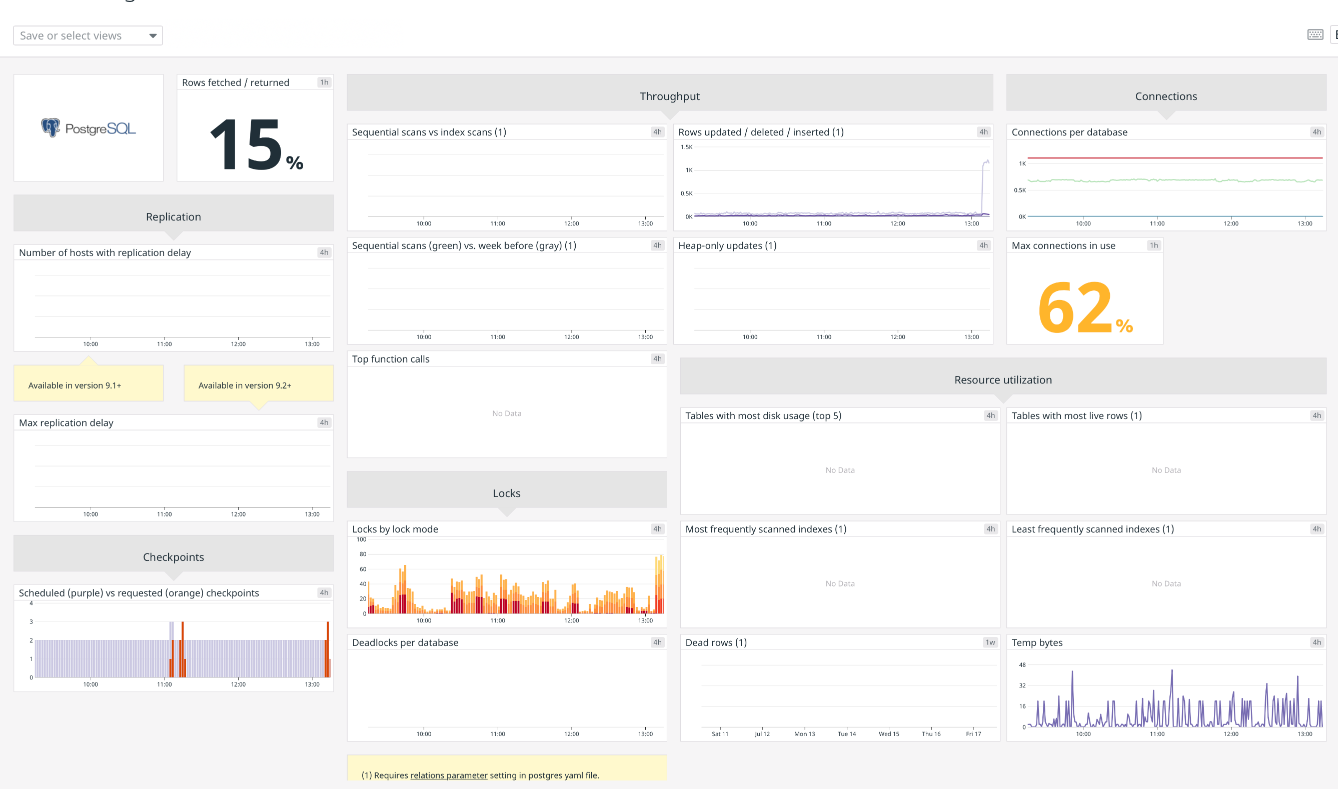
Если у вас есть хоть какой-то продакшн, который до сих пор не обложен цифрами — прикрутите к нему APM. Не хотите Датадог — есть куча конкурентов: New Relic, AppDynamics, AppOptics, Elastic APM.
