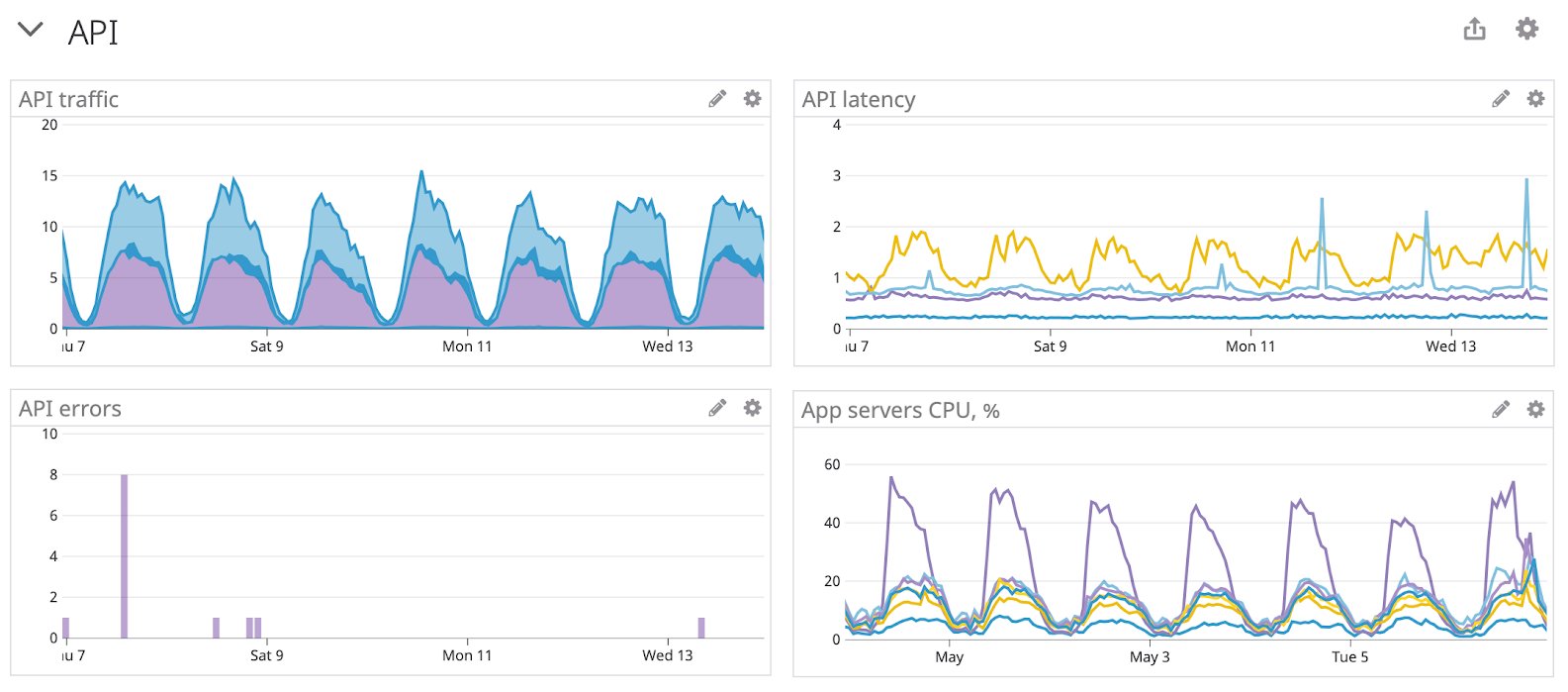
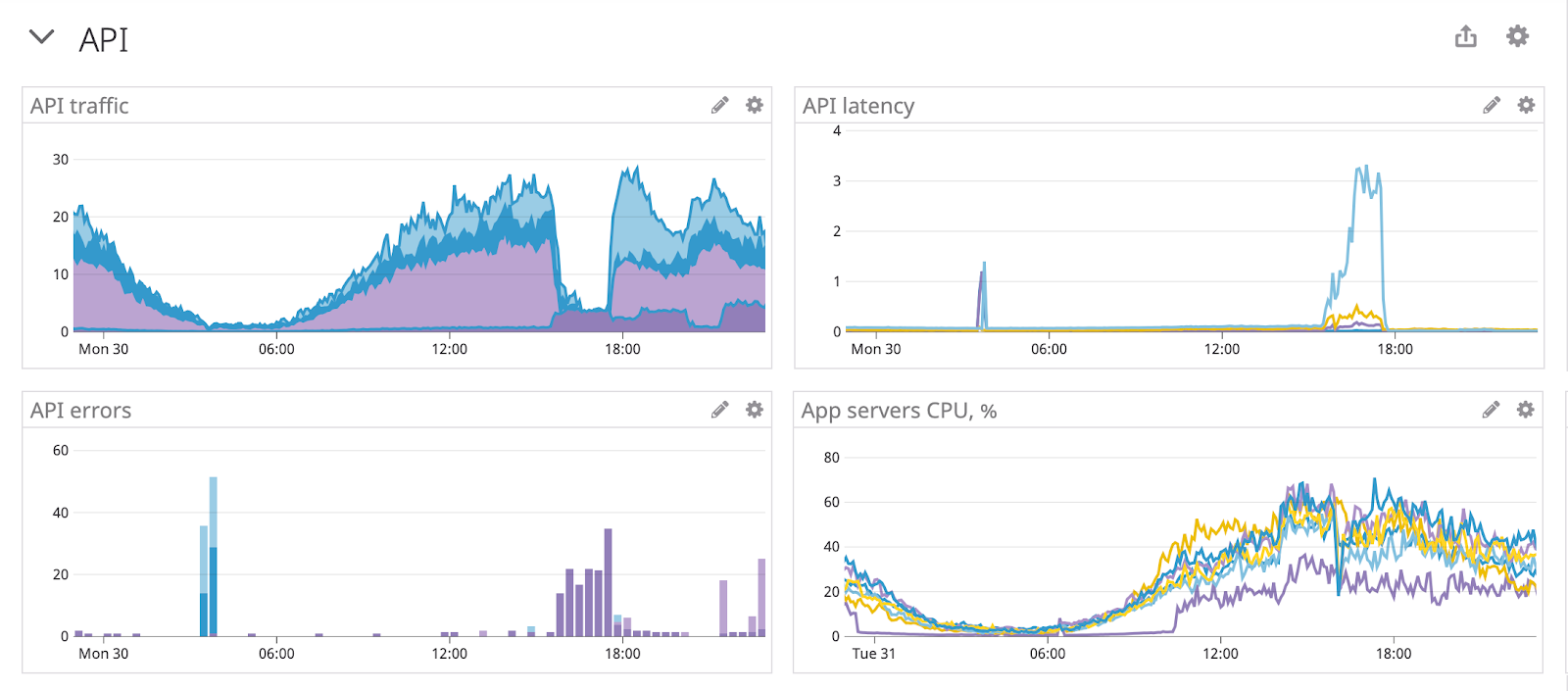
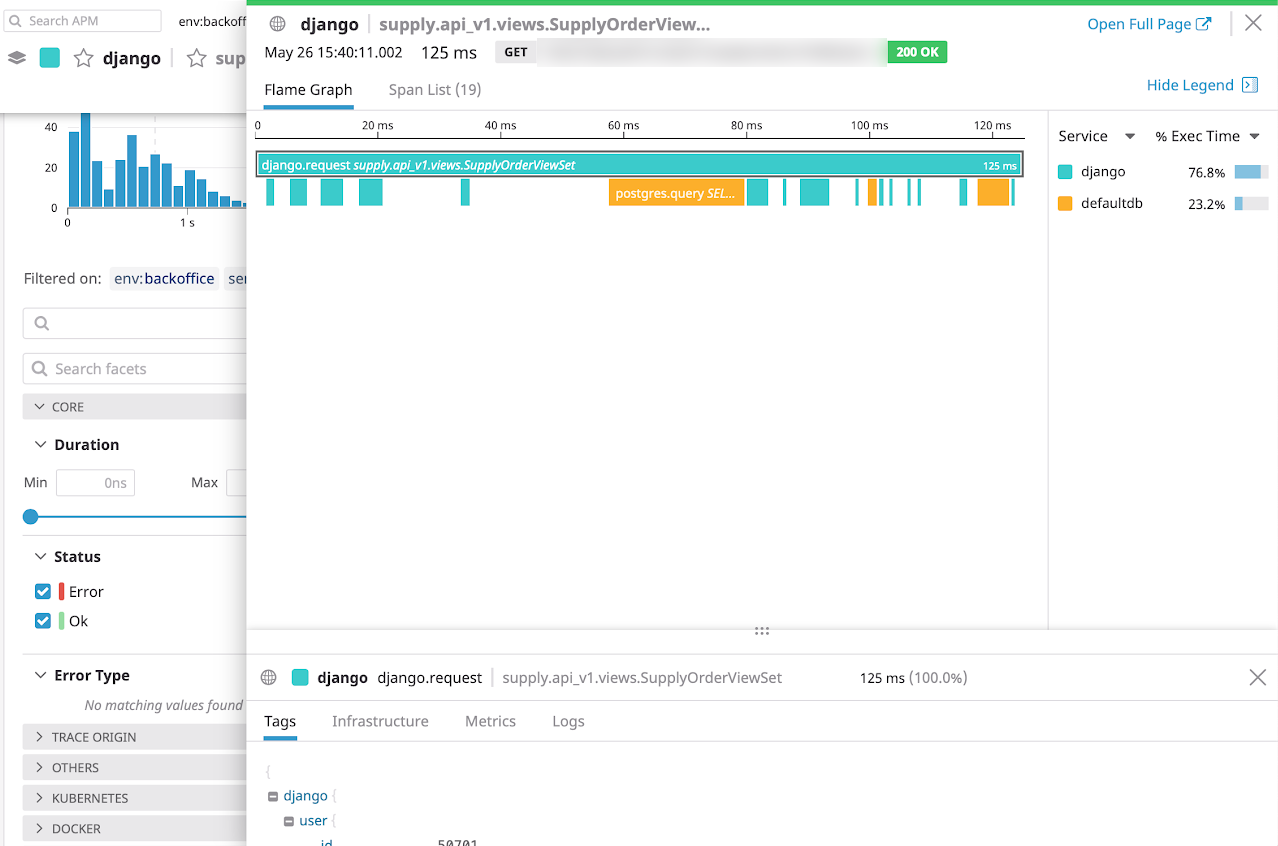
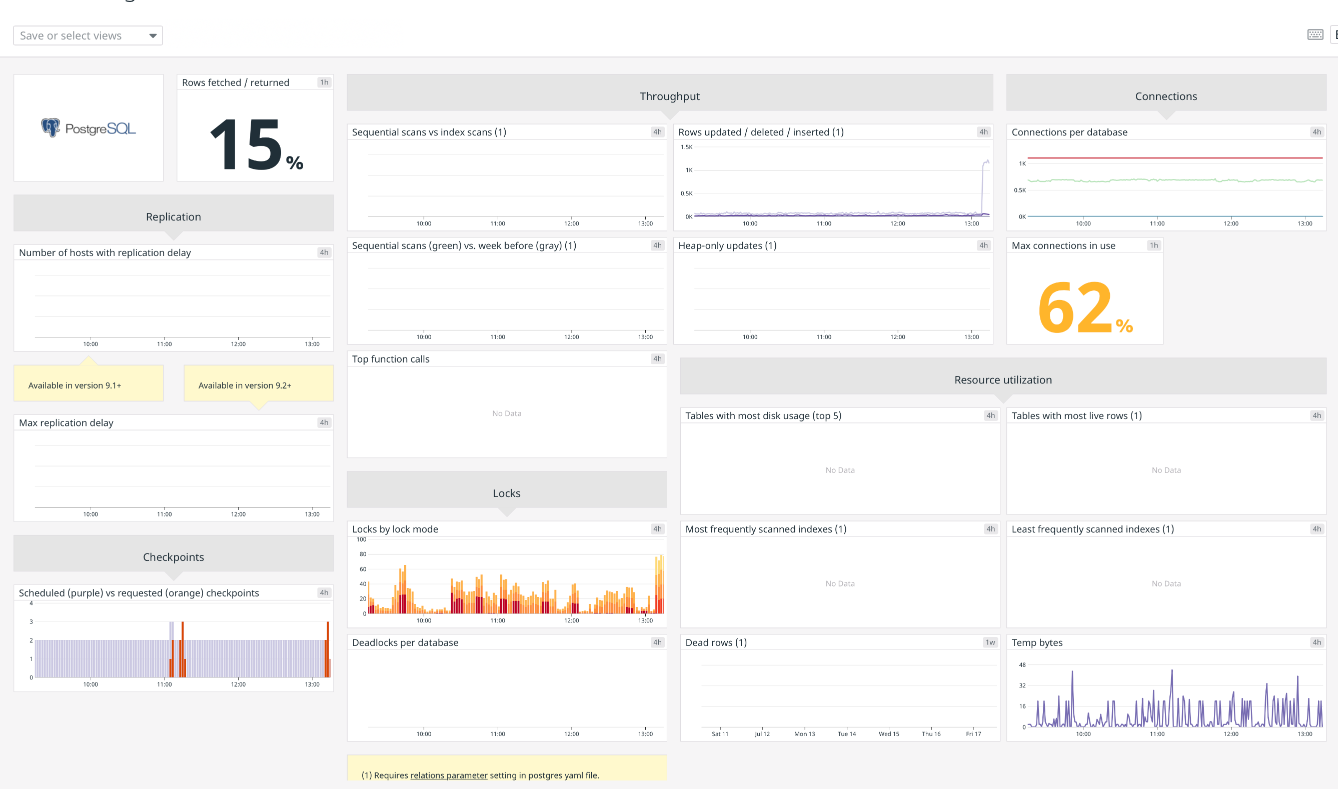
Как изменилось моё отношение к огородикам
С 2018 года я публично ругаю привычку многих админов тащить с собой ИТ-инфраструктуру: поднимать локальные GitLab и Sentry, использовать собственные сервисы вместо PaaS, DBaaS и прочих -aaS. Вот пост об анализаторах логов и огородиках, с которого всё началось.
После 24 февраля меня стали спрашивать, насколько поменялось моё отношение к внешним сервисам, многие из которых в один момент взяли и перестали обслуживать (российскую) часть своих пользователей. Попробую ответить.
В использовании заёмной инфраструктуры всегда есть риски. Текущие события — всего лишь один из большого количества рисков: подводные лодки рвут морские кабели, бандиты вламываются в датацентры, а ваш поставщик услуг просто молча отваливается на две недели. Вообще, все наши ИТ-шные риски — это тоже только часть угроз, которые нависают на бизнесом: есть ещё финансовые, правовые и репутационные риски.

Когда бизнес только-только открывается, рисков — куча: у собственника нет денег на дорогих юристов и программистов, не получается собрать финансовую подушку (а та, что получилась, лежит в том же банке, что и основной счёт). Компания может просто не попасть в рынок, или на этот рынок придёт условный Яндекс заберёт себе клиентов через новый Яндекс.Всё.
По мере роста владельцы защищаются от рисков — нанимают больше профессионалов, забирают себе больше инфраструктуры, выходят на другие рынки, чтобы диверсифицировать бизнес. Точно такая же картина и с SaaS-ами. Если вы стартап — у вас по прежнему нет ресурсов на операционную поддержку собственных огородиков. По мере роста вы становитесь всё более и более независимы. Когда дорастаете до Амазона — строите собственные датацентры.
После 24 февраля поменялся только набор SaaS — больше нет Mailchimp, Slack или продуктов Atlassian. Но у всех этих сервисов есть менее крупные аналоги, которые продолжают работать с русскими. Да и отечественный производитель не отстаёт — у большинства сервисов уже есть замены. И пусть эти замены обычно выглядят как жигули, и от езды на них болит спина — они всё равно снимают с бизнеса огромное количество нагрузки: вам не нужно мониторить серверы, обновлять версии ПО, разбираться в протоколах взаимодействия сервисов друг с другом.
Так что огородики — это норм, если вы можете себе позволить не есть огурцы с рынка. А если не можете — для вас картина сильно не поменялась.