Как мы запустили мобильное приложение на веб-технологиях и нам чуть не помешал Apple
Мы с клиентом запустили стартап. Он помогает малым локальным бизнесам — кофейням, барбершопам и другим — зарабатывать по модели, которую применяют Amazon и Яндекс.
Сделали мы это с помощью технологии PWA — создали практически полноценное мобильное приложение: с офлайном, пуш-уведомлениями и иконкой на рабочем столе. В этой статье делимся, как у нас получилось успеть всё это за 6 месяцев при том, что требования постоянно менялись (стартап же!)
Что за проект
Большие цифровые бизнесы зарабатывают кучу денег на пакетах и подписках. Пакеты повышают средний чек, а подписки помогают получать регулярную прибыль и планировать бюджет. Amazon и Яндекс продают пакет-подписку сразу и на кино, и на доставку товаров. Apple давно сместил фокус с продажи отдельных песен на подписку на Apple Music. Пользователь тоже выигрывает — если вы постоянно пользуетесь сервисами Амазона, месячная подписка отбивается за неделю.
Если вы — владелец кофейни, и хотите продать постоянным клиентам подписку на капучино по утрам, есть нюанс: у Амазона и Яндекса есть миллионы долларов на программистов, а у вас, скорее всего, нет.
Тут на помощь приходит Dozo — проект, в котором собственную подписку или пакет может создать любой малый бизнес — от кофейни до барбершопа.
Вот они, подписки:
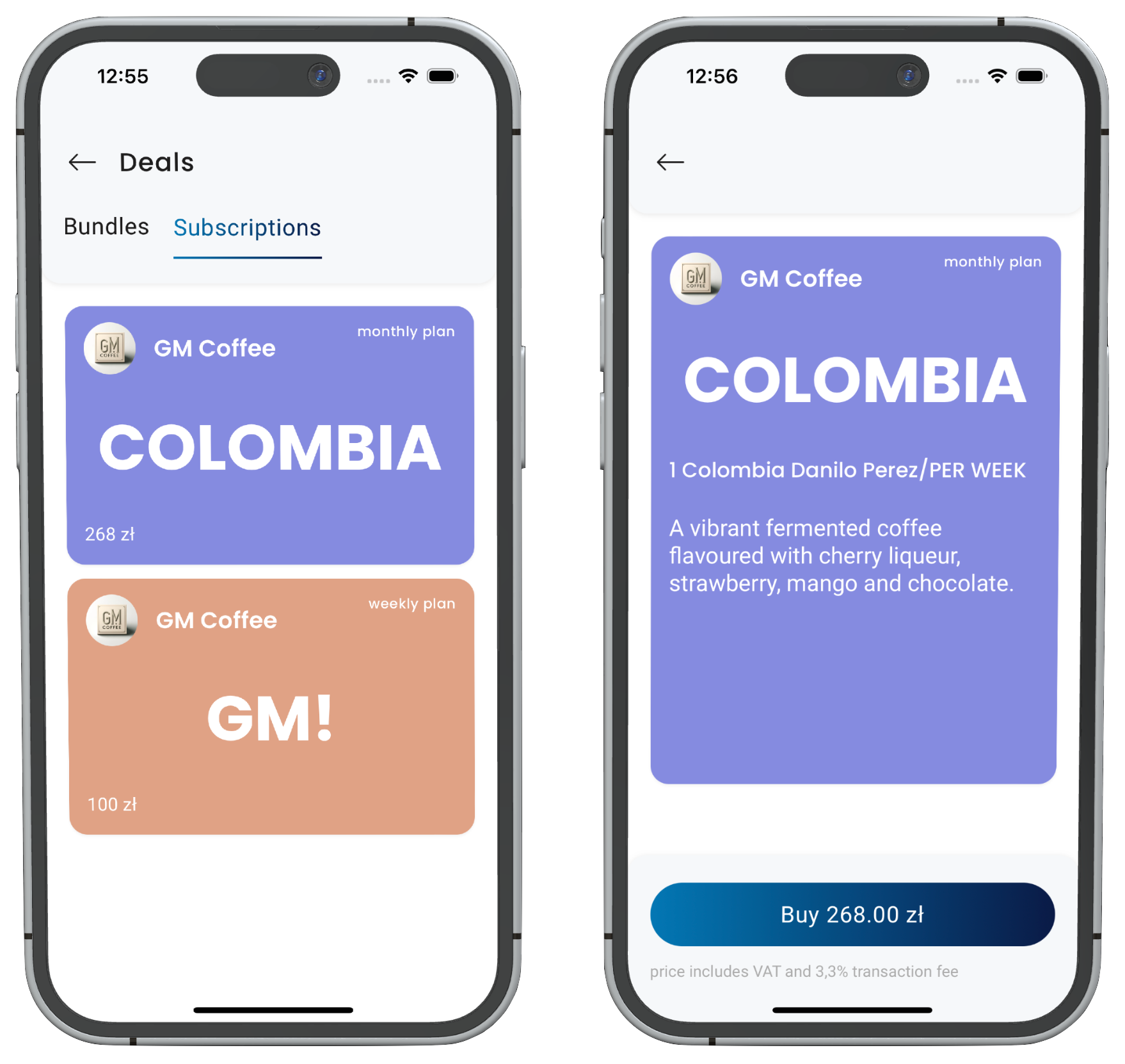
На первый взгляд, это довольно простой проект — каждый зарегистрированный бизнес создаёт свои подписки и пакеты услуг, а клиенты открывают их по QR-коду и покупают прямо в приложении.
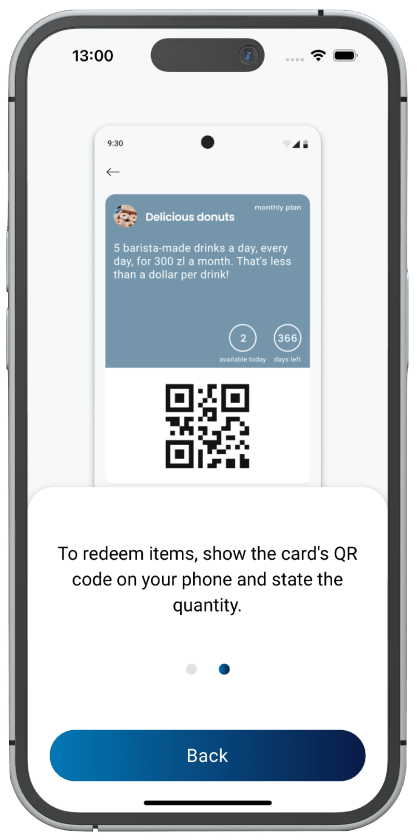
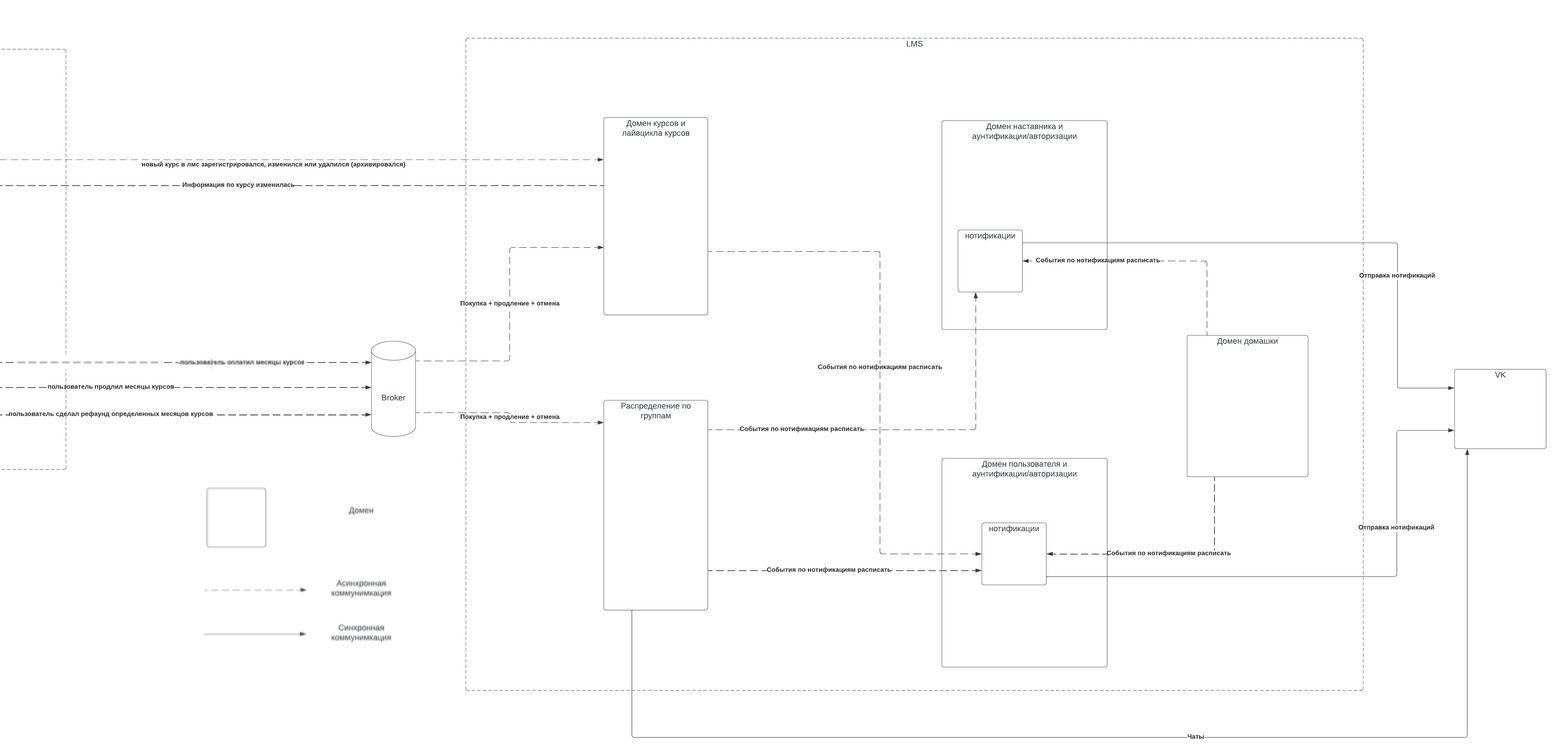
На самом деле, в нём довольно много нюансов — барбершопу и кафе нужны разные форматы меню; у одного владельца может быть несколько бизнесов, а у одного бизнеса — несколько локаций; каждому сотруднику нужна учетная запись с возможностью считывать QR-коды клиентов, но без возможности менять настройки бизнеса; владельцу бизнеса важно видеть статистику; нужна интеграция с Google Maps, платежным провайдером и SMS API; нужно правильно учитывать налоги при приёме платежей.
Работа над проектом
Любой программист знает, как больно работать с меняющимися требованиями. В этом проекте этого было очень много. Мы вместе с клиентом составили список User Stories и обновляли его после каждой встречи. Это давало уверенность, что при пересмотре планов мы не забудем ничего важного:

На старте планировали две страны и чат между пользователем и бизнесом. Через месяц стало понятно, что для тестирования гипотез хватит и одной Польши, а чат можно вообще отложить. При этом есть другие супер-важные фичи — генерация листовок с QR-кодами, или меню, где можно узнать список услуг: без них проект не запустится. А ещё отдельная история — это уведомления. Из-за того, что Apple грозились сломать пуши, а потом передумала, задачу то переизобретали, то убирали из планов, то возвращали в работу.
Для стартапа, который только пытается нащупать своё уникальное товарное предложение, найти своё место на рынке, такие резкие перемены — нормальное положение дел.
Перед тем, как написать первую строчку кода, ведущий бэкендер проекта Лёша продумал архитектуру: провёл с клиентом сессию Event Storming и построил модель данных по контекстам. Это помогло разделить стабильные и часто меняющиеся части системы — быть гибкими, но стойкими.
Технологии
На бэкенде использовали Python и Django, на фронтенде Vue.js — проверенный стек, с которым у нас большой опыт и экспертиза. Для инфраструктуры использовали проверенные решения: GitHub Actions, Cloudflare и Heroku, для SMS-рассылок подключили Twilio. Для мониторинга взяли Hosted Graphite — стоит дешево, настраивается быстро. Задачи менеджили в привычном нам Бейскемпе.
Прием платежей сделали с помощью Stripe Connect — готового решения для маркетплейсов. Деньги приходят владельцам локальных бизнесов, а Dozo автоматически получает комиссию. Идеально!
В Dozo два языка: польский и английский. На старте работы макеты были только а английском. Чтобы упростить жизнь клиенту, файл с текстами переводили на польский с помощью ChatGPT, а клиент проверял результат и исправлял ошибки. Еще схема с ChatGPT сильно помогла фронтендерам с версткой: примерная длина строк на обоих языках была понятна сразу. Если бы переводов было сильно больше — подумали бы интеграцию со специализированными API для локализации вроде DeepL, но в случае Dozo это оверкил.

Ещё одна вещь, которую мы делали в первый раз — интеграция с Apple и Google Wallet. Карточки товаров из Dozo можно хранить и показывать из родных интерфейсов iOS и Android без запуска Dozo, прямо как авиабилеты. Кстати, наши карточки в электронных кошельках динамические — то есть информация в них регулярно обновляется. Если в вашем проекте нужны wallet-ы — не оставляйте задачу на последние спринты, потребуется время, чтобы разобраться с кастомизацией карточек и обновлением данных.
PWA
Dozo это PWA (Progressive Web App) — сайт, который выглядит и работает как приложение. У него куча плюсов:
- в отличие от сайтов, оно умеет открываться и работать оффлайн, без интернета;
- его можно вытащить на рабочий стол, прямо как приложение;
- у обычных сайтов, на экране постоянно висят кнопки «вперед, назад» и адресная строка, у PWA браузерные контролы скрыты, только наш интерфейс, как у приложений;
- одно и то же приложение работает сразу и на iOS, и на Android;
- не нужно проходить жёсткое ревью для каждого обновления.
Если пользовались мобильным сайтом Сбербанка или Тинькофф Банка в 2024-ом году, скорее всего вы сталкивались с этой технологией. Примеры из международного рынка — PWA приложения AliExpress, Twitter, Starbucks и Pinterest.
Невооруженным глазом PWA не отличить от мобильного приложения из Google Play или App Store:
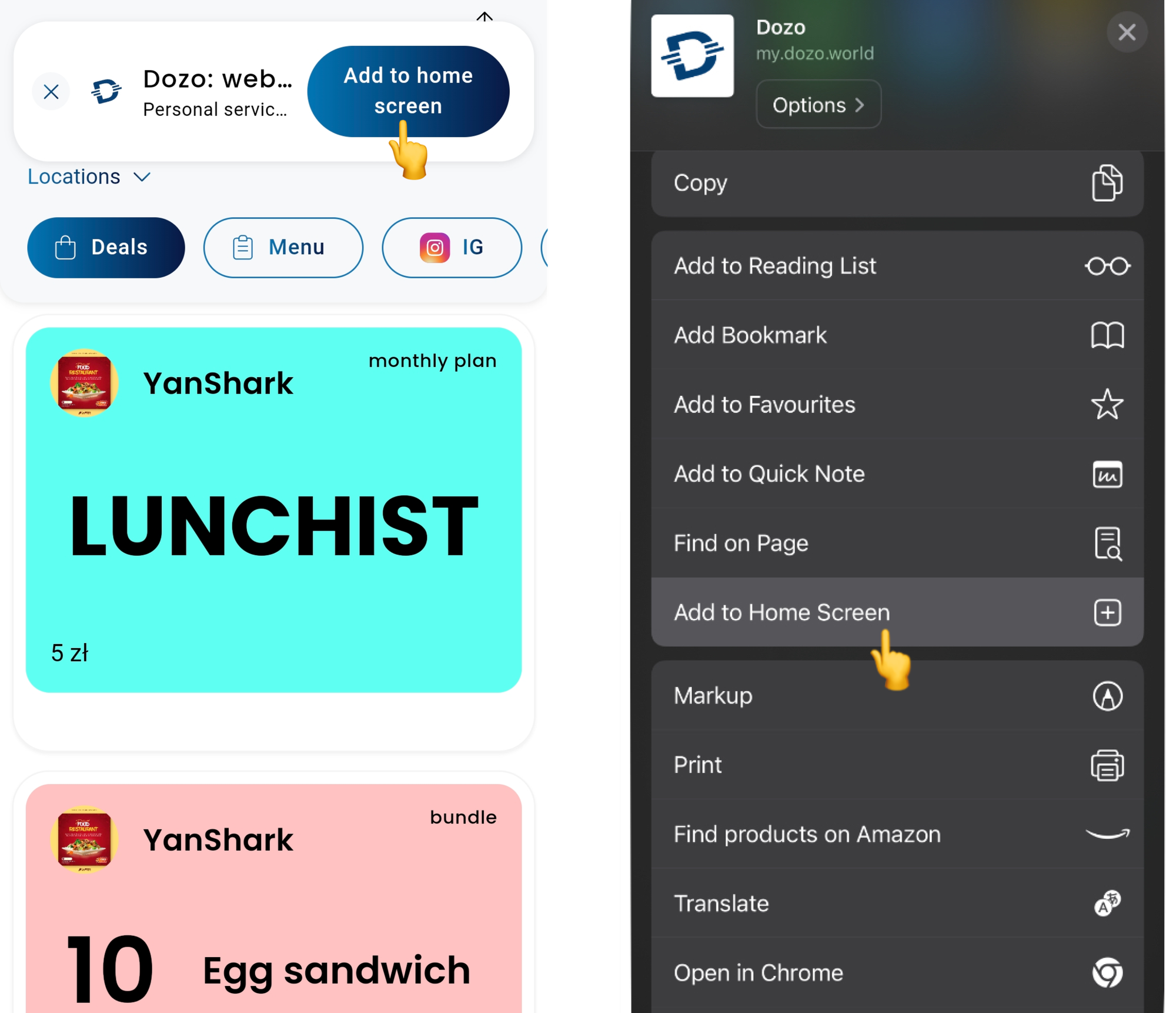
Есть и минус — на iOS нельзя выкладывать PWA в App Store, а значит пользователям гораздо тяжелоее добавить икноку на рабочий стол.
На Android (слева) можно сделать кастомную кнопку установки PWA из браузера, мы сделали баннер наверху экрана. На iOS (справа) такой возможности нет, единственный вариант— зайти в настройки сайта и нажать Add to Home Screen:
Риски PWA мы взвешивали вместе с основателем и CTO Dozo, и решили, что в нашем случае плюсы перевешивают минусы.
Как мы попали в замес борьбы двух Голиафов
Итак, два месяца до запуска. Работа расписана по дням, время — ударно допиливать фичи и запускаться. В начале февраля Apple объявляет, что выключает PWA для европейских пользователей в следующем обновлении iOS.
На примере Spotify: слева как выглядит PWA на iOS 17.3.1, справа — на iOS 17.4 Beta 3. Слева, считай, приложение, справа — вкладка в браузере.
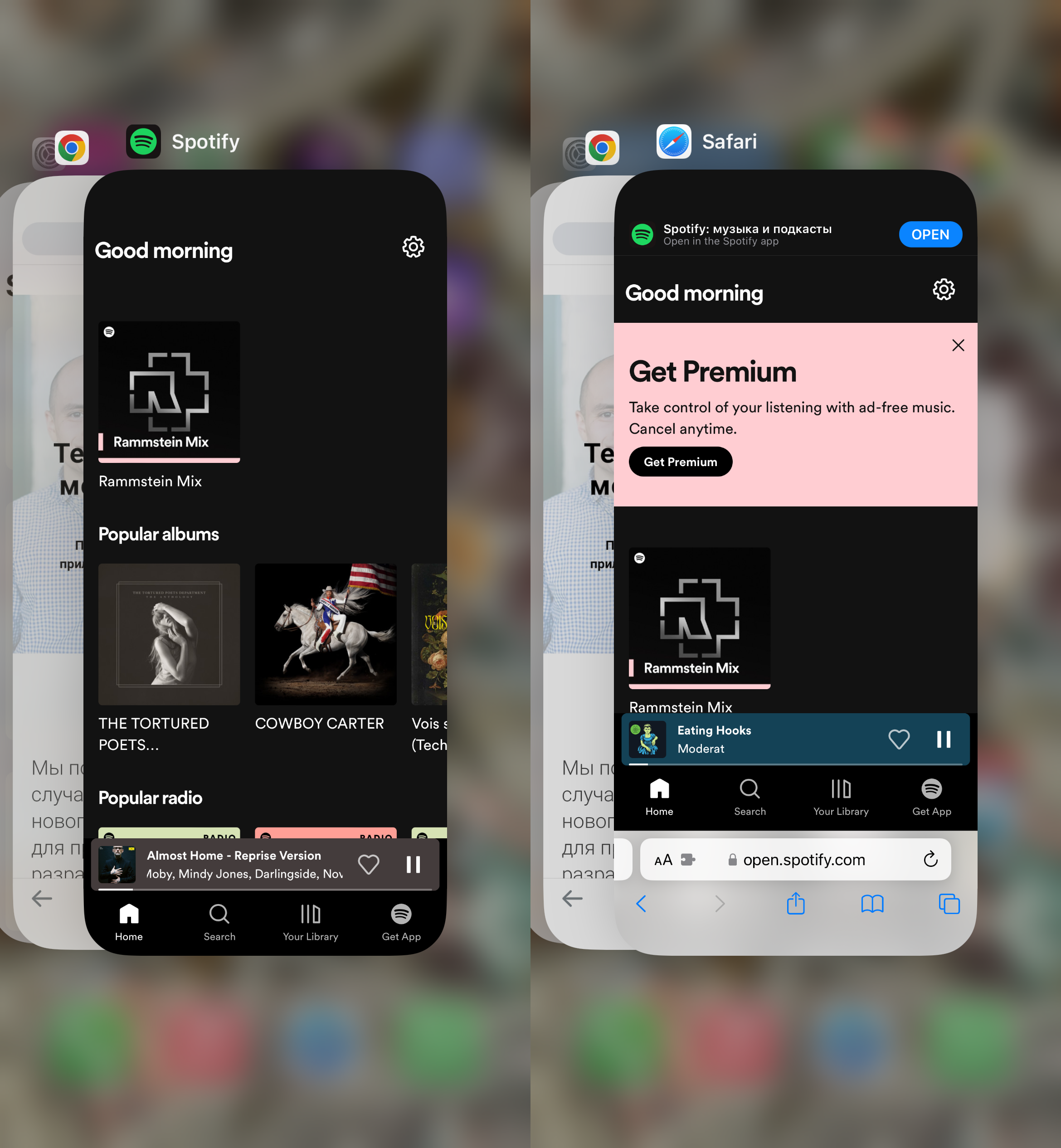
Дело в том, что незадолго до этого Евросоюз принимает закон о защите конкуренции, по которому владельцы платформ (читай Apple) не имеют права ограничивать установку сторонних программ на свои устройства. Apple нехотя подчиняется, но в ответ портит пользовательский опыт для жителей ЕС — мол, вините в этом своих политиков. Есть много мнений и аргументов о том, кто прав в этом споре.
Для нас же это выглядит как сход лавины в горном походе. Сетовать на несправедливость мира глупо, нужно искать путь в обход. Есть несколько вариантов, самый очевидный — засунуть сайт в нативную обертку, типа Capacitor-а, тогда для Apple мы будем выглядеть как самое обычное приложение. Проблема в том, что времени у нас осталось в обрез, а продакшен-опыта с Capacitor у нас не было. Решили запускаться на iOS просто как сайт.
К счастью, через несколько недель после анонса отключения PWA, Apple поменяла свое решение (кажется, сыграли роль в том числе и крики разработчиков в соцсетях) и мы запустились как планировали, со всей функциональностью, но нервы это потрепало и нам и клиенту.
Финал
От подписания договора до запуска MVP прошло шесть месяцев. Первые два месяца мы вели подготовительную работу, следующие четыре — активную разработку. Основную работу с нашей стороны сделали два бэкенд-разработчика, два фронтенд-разработчика и руководитель проекта.
Если вы живете в Варшаве — скоро сможете купить подписку на стрижки в барбершоп или комбо из капучино и булочки со скидкой в кофейне через Dozo. А наша команда продолжит поддерживать и развивать продукт после запуска.
Если хотите запустить проект с нами — пишите в телеграм или оставьте заявку на нашем сайте.
Команда
Андрей Бацунов, фронтенд-разработчик,
Алексей Богословский, ведущий бэкенд-разработчик,
Артур Даценко-Боос, фронтенд-разработчик,
Полина Никитина, бэкенд-разработчица,
Иван Седов, фронтенд-разработчик,
Инна Сидорова, руководитель проекта.