Создатели опенсорс-инструментов совершают продуктовые ошибки ещё чаще, чем предприниматели.
Каноничный пример — python-telegram-bot. Хороший, вроде бы, фреймворк: приемлемый бойлерплейт, поддерживает все нужные эндроинты, в документации разобраться тоже возможно.
Но вот несколько лет назад его взяли и переписали на asyncio. Получилось очень по-программистски: авторы не надели шляпу пользователей, у которых уже есть кодовая база. Хочешь новые фичи и секьюрити-фиксы — будь добр, переписывай кодовую базу под никому не нужный async. Авторы даже не удосужились как-то продать юзерам ценность перехода, добавить хоть каких-то фич. Просто переписали и всё — в анонсе нет вообще ни капли смысла, одни только «embracing the future».
Оно и понятно — откуда взяться смыслу, если у PTB в принципе не может быть задач, для которых нужен event loop. Если есть большая нагрузка, как, к примеру, у антиспам-ботов, то её легче обработать без фреймворка, в рамках отдельного потока. А если нужно дизайнить развесистый флоу общения с пользователем (для чего вобщем-то и нужен PTB) — скорее всего этот флоу никогда не нагрузят так, что там понадобится асинхронщина.
Самое смешное в этом переходе — фреймворк даже на asyncio продолжает быть однозадачным: не будет отвечать одному юзеру, пока обслуживает другого. Чтобы включить интуитивно ожидаемое поведение, надо в бойлерплейте писать какое-то странное заклинание, что-то вроде bot.init(simultaneos_updates=True).
Я всю профессиональную жизнь связан с разработкой. Видел много нормально запроганных, но мёртвых проектов, в которых создатель просрал продуктовую работу. Видел много успешно работающих проектов, где разработка была полным дерьмом даже без юниттестов — но создатель делал продуктовую работу на отлично, и проект, пусть и со страдающими программистами, но ехал вперёд.
И ни разу я не видел проекта, который не запустился из-за медленной разработки.
Конечно, в долине смерти много бизнесов, где код говно, а программисты нарушают обещания. Но причина их смерти — не в программистах, а всё в той же просранной продуктовой работе: нулевой product-market-fit, несходящаяся экономика, неумение нанимать людей и тестировать гипотезы.
Плохой код — следствие общих проблем, а не причина
Когда пойдёте на следующий курс по вайб-кодингу, чтобы заменить своих программистов, вспомните пожалуйста меня — ваш проект умрёт не из-за программистов, не из-за бухгалтеров и не из-за поставщиков воды в офис. Он умрёт из-за вас.
В «Коммуникации Систем» мы много говорим о понятиях system form и system function. Форма — это как система выглядит: на какие модули разбита, с какими данными работает. Функция — то, что система делает: как реагирует на ввод, что отдаёт на вывод.
Форма и функция выходят далеко за рамки IT и проектирования. Это, скорее, про красоту. Вещи, в которых форма подчинена функции — красивы. Вещи, в которых функция размыта, а форма сложна — некрасивы и неприятны.
К примеру макбуки, Dell бизнес-серий, дорогие thinkpad — красивы: дают много возможностей владельцу и не отвлекают формой. Игровые ноутбуки и всякие дешёвые асусы — некрасиво, потому что их главная функция — блистать на полке в магазине. Есть и исключение — Framework: вроде бы и красивые штуки, но вот функция, которую они выполняют, — быть ремонтопригодный в домашних условиях, — вряд ли понадобится кому-то в здравом уме.
А сколько же на улице некрасивых машин! Дорогие немцы, в большинстве своём — некрасивы: функции размыты, а форма требует постоянного обслуживания. Исключение — разве что Майбахи, заточенные под перевозку одного пассажира, или BMW M-серии, сделаные для кольца: с такими функциями можно и хрупкую форму потерпеть. Маленькие SUV, которыми забит рынок — некрасивы: форма как у дешёвых ноутбуков, пригодна только стоять в автосалоне и говорить неискушённому потребителю «не думай, купи меня, я сгожусь на любой случай жизни».
Чувство прекрасного отдыхает на утилитарных пикапах вроде Toyota Tundra или том, что в штатах называют «траками»: они много возят, когда надо — быстро едут, а простое шасси и атмосферный мотор будут хоть 20 лет выполнять свою функцию. Очень красивы велосипеды на которых ездят курьеры: быстрые, лёгкие, ничего лишнего.
Глядя на форму, можно определить функцию, которую туда закладывает автор. Так, по названию хорошего класса в коде понятно, что он делает, а по первому экрану приложения видно, чего от него хотели авторы.
Форма эволюционирует вместе с функцией. К примеру Медиум когда-то был отличным средством для публикации лонгридов, а в процессе эволюции превратился в пейвольную помойку — очевидно, новая форма стала более выгодна владельцам. Или взять любой продукт Яндекса — почти везде его функция со временем перестаёт интересовать владельцев. Так навигатор превратился в тормозные «карты», а сервисы доставки еды и такси превратились в мигающий попапами и требующий кучи лишних кликов Yandex Go. Вообще, «экосистема» это что-то на шейрхолдерском, а не на пользовательском.
Когда проектируете что угодно — архитектуру системы, пользовательский опыт, пост в тг-канал — сначала подчиняйте форму функции, а потом уже думайте об украшениях.
Задумался тут, что количество подписчиков в телеге, да и в любом другом блоге — это как оборот у бизнеса. Почему-то предприниматели, когда рассказывают о своём бизнесе, обязательно меряются оборотами, но никто не говорит о маржинальности и прибыли.
Допустим у кого-то бизнес с оборотом 500 миллионов рублей в год, из которых 200 уходит на закупку товаров, 200 на зарплаты, а 95 — на обслуживание кредитов. Получается внушительная цифра, но вот прибыли не много. Или возьмём бизнес в 10 раз меньше — 50 миллионов в год, о при этом затрат у него только 10 миллионов. Второй бизнес хоть и выглядит скромнее, но гораздо более прибыльный. Я-то уж точно выберу второй.
Так же и с количеством подписчиков. Есть каналы с десятками тысяч людей, которых читает от силы 1000 человек. И наоборот, бывают каналы по 2000 человек, где просмотров больше, чем подписчиков. Среди SMM-щиков этот показатель называется уровнем вовлечённости — средний процент просмотров относительно общего количество подписчиков.
Но на самом деле уровень вовлечённости — тоже не самый полезный показатель. Гораздо важнее смотреть, насколько канал решает задачи, которые перед ним поставил автор. Через эту призму уровень вовлечённости и абсолютные цифры просмотров становятся важны только для брендовых каналов или медиа — там важны охваты и продажа рекламы. А для простых ребят, которые ведут канал, чтобы высказаться, получить новые контакты или полезные комментарии, гораздо важнее качество аудитории: насколько людям интересно читать и отвечать.
Если канал предлагает какой-то продукт — нужно смотреть, какому проценту аудитории этот продукт может быть полезен. К примеру ютуберы с миллионными каналами вынуждены зарабатывать с рекламы, а не со своих продуктов потому, что их миллионы — это гетерогенная масса случайных людей, из которых не получается выделить когорту, достаточную, чтобы собрать ценный продукт, который приносит деньги.
Сравните две крайности — у Тонского маленький канал с супер-интересными срачами в комментах, а у Лебедева — гигантская площадка медийного уровня, но вот услуги студии он там давно не продаёт.
Вебиум — онлайн-школа для подготовки к ЕГЭ. 30 тысяч школьников, тысяча наставников, 20 тысяч вопросов и 2 тысячи домашних заданий на сотни тем.
В 2021 году у Вебиума уже была рабочая система на Ruby, которую разрабатывали подрядчики-аутcорсеры. К нам они обратились с привычной проблемой — подрядчики медленно пилят фичи. Посмотрев код и оценив возможности команды, мы поняли, что рефакторить существующий код — долго и дорого, и решили перезапустить систему своими руками на привычном стеке — Django и Nuxt.js. Справились за год: с сентября 2022 все ученики покупают и проходят курсы в новой системе.
Перед нами стояли 3 задачи:
Сделать так, чтобы фичи, которые хочет бизнес, разрабатывались быстрее и более предсказуемо. Обострённый пример: «давайте добавим вот эту маленькую штуку; конечно, будет завтра (возвращаются через две недели), ой нет, это займёт полгода» (и это ещё хорошо, если вернутся с таким честным ответом).
Нанять технического директора и создать внутреннюю команду разработки, чтобы в будущем не зависеть от аутсорса.
Сделать всё это «на лету», без остановки образовательного процесса и потерь для бизнеса.
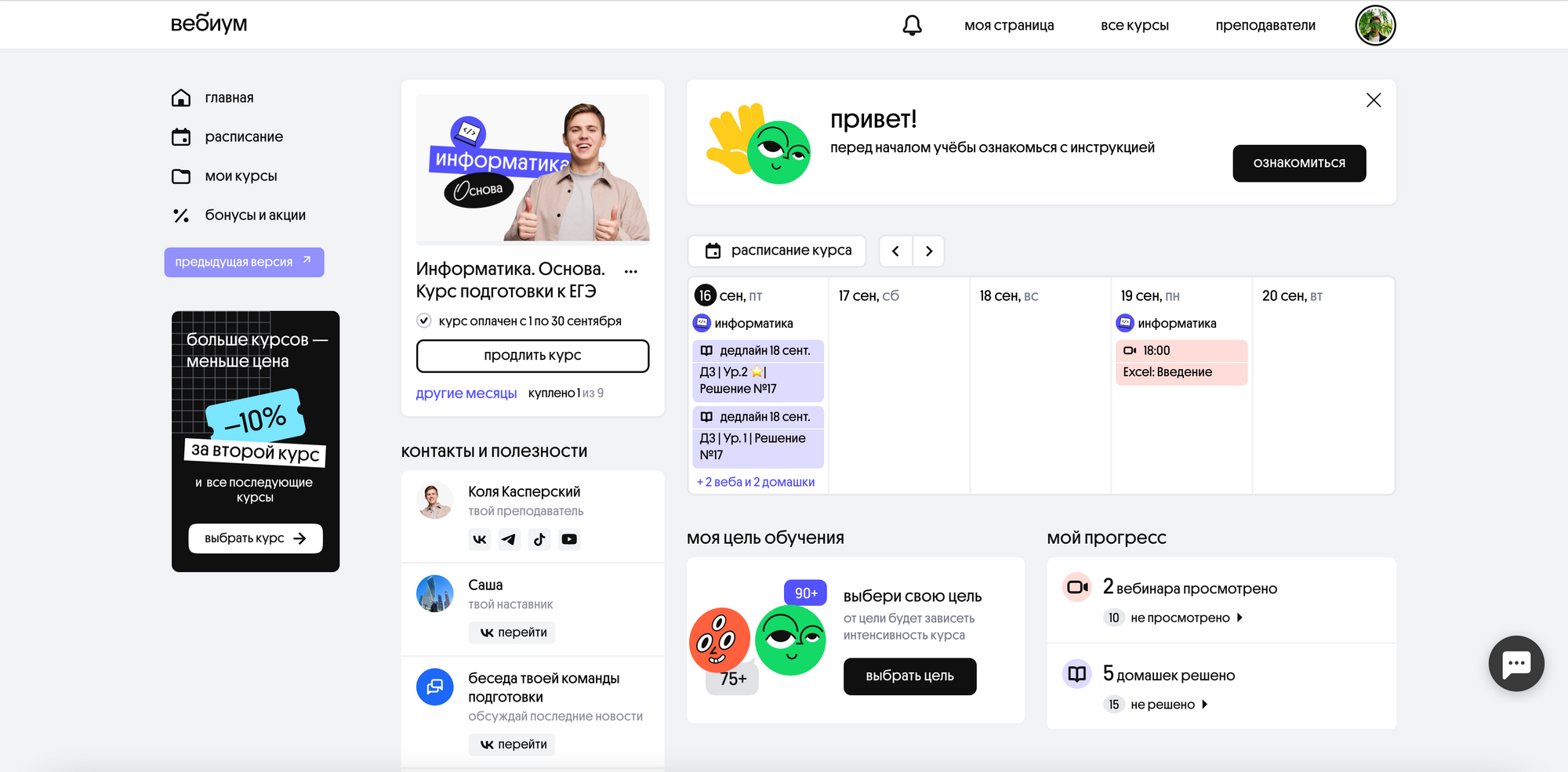
Главная страница Вебиума — онлайн-школы, которую ждал нескучный перезапуск
Дедлайн всего проекта — сентябрь 2022. Министерство образования не станет переносить ЕГЭ из-за того, что мы не успели доделать, например, отправку уведомлений в VK.
Чтобы не подписываться сразу на гигантский годовой проект, мы разбили работу на 2 больших этапа — запуск нового магазина и запуск новой платформы обучения (Learning Management System, LMS). Магазин – часть сайта, где школьники и родители покупают курсы. В LMS школьники учатся: смотрят вебинары и учебные материалы, решают задания и общаются с наставниками.
Благодаря такому разделению мы смогли запустить магазин не дожидаясь разработки новой LMS. Но есть и сложность — пришлось подружить новый магазин со старой LMS, которую разрабатывает чужая команда.
Часть первая: перезапуск магазина. Сентябрь 2021 - февраль 2022
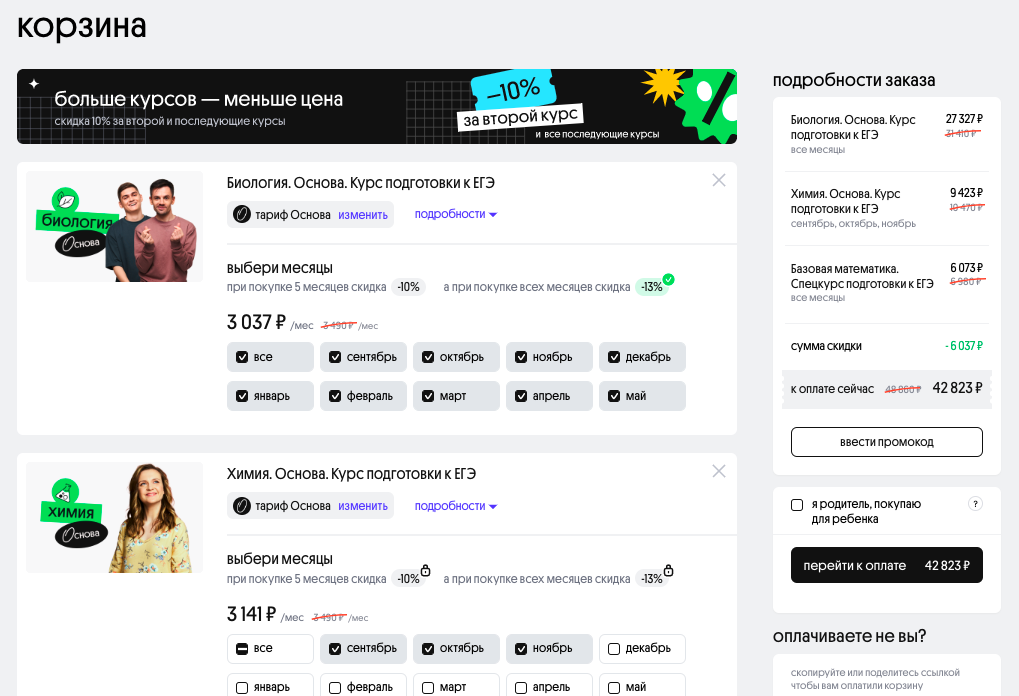
Перезапуск магазина давал два ключевых профита бизнесу: корзину и прозрачную аналитику. В старом Вебиуме было серьёзное продуктовое ограничение — можно было купить только один курс в одном чеке. Хочешь второй курс — проходи всю корзину ещё раз. Это плохо и для бизнеса и для учеников. Для бизнеса — это низкий средний чек, а для учеников это ухудшает качество наших услуг — ни один ВУЗ не принимает студентов по результатам только одного предмета. Технический ВУЗ может требовать информатику и математику, фармацевтический — химию и биологию, и почти везде требуется русский язык.
Нам нужно было сделать удобную корзину: с возможностью купить сразу пачку курсов и получить за это скидку. А ещё в старой системе было плохо с аналитикой — нам нужно было сделать структуру данных, которая не вызывает желания постричься в монахи. Серьёзно — посчитать важные для бизнеса показатели вроде выручки или количества проданных месяцев на старой системе стоило несколько дней ручной работы, потому что эта информация хранилась в JSON-ах с разнородным форматом.
Вот так выглядит корзина в новом магазине
Архитектура
Мы сделали две системы: наш магазин отвечал за продажи курсов, а обучение мы оставили в старом монолите на Ruby. Конечно, у каждой системы мы сделали отдельную БД — если бы мы переиспользовали старую, то притащили бы все болячки аналитики.
При переносе пользователей заметили отклонение от правила Парето — мы перенесли 99% (!) пользователей и считали свою работу успешной. Но выяснилось, что 1% оставшихся пользователей делали у нас кучу заказов, и они настолько важны для бизнеса, что без них задачу нельзя было считать решённой. На перенос этого 1 золотого % у нас ушло больше времени, чем на 99% остальных!
Система, которая как-то работает, у Вебиума уже была. Перед нами стояла задача сделать систему, которую будет удобно поддерживать и развивать будущей ин-хаус команде Вебиума. Новая система получалась сложной, поэтому мы с самого начали наняли Антона Давыдова на роль архитектора. Он разобрался в деталях бизнеса и спроектировал основные составляющие системы ещё до того, как мы написали первую строчку кода, а самое главное — оставил понятную документацию, которая сильно ускоряет погружение новых программистов в работу над Вебиумом даже после нашего ухода.
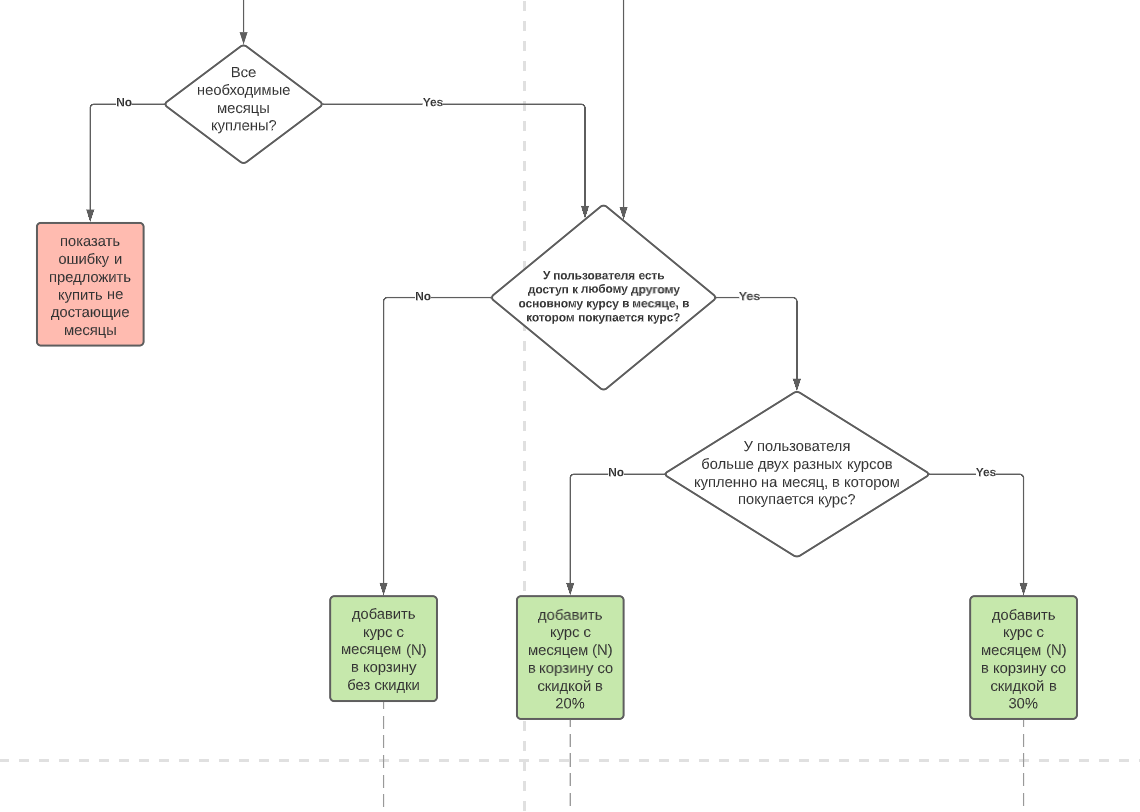
Кусочек функциональной схема добавления товара в корзину с учетом скидок. Нужно учесть много edge-кейсов — вся схема в 5 раз больше.
У старой и новой системы 2 ключевые точки соприкосновения: пользователи и покупки. Для пользователей мы придумали однонаправленный поток данных с новым магазином в качестве источника правды. Регистрация и изменение пользователей происходит на стороне магазина. События об изменениях стримятся в старую LMS. Если студент заходит на страые страницы управления профилем в LMS — мы его редиректим на магазин.
Открытие доступов к курсам тоже работает однонаправленно: при покупке курса в новом магазине создается событие, в ответ на которое старая LMS открывает доступ студенту. Отправка событий построена на RabbitMQ.
Инфраструктура
Для маршрутизации трафика мы использовали уже проверенную на Снобе комбинацию из traefik и Express.js. Express.js выполняет роль BFF (Backend for Frontend). Это быстрый прокси-сервер, у которого несколько важных функций:
SSR (Server Side Rendering) важных с точки зрения SEO-страниц. Поисковики — важный источник трафика для Вебиума.
Управление аутентификацией. Мы вместе с аутсорс-командой старой системы спроектировали и запрограммировали систему кросс-аутентификации: вход/выход в одной системе автоматически приводит к входу/выходу в другой системе.
Маршрутизация запросов между новой и старой системой. Благодаря прокси комбинация из нового магазина и старой LMS выглядела единой системой для пользователя.
Все неизвестные пути Express.js направляет на обработку в legacy-систему. Если после запуска нужно откатиться на старую систему — мы просто отключаем прокси. Старая система продолжает работать как ни в чём не бывало.
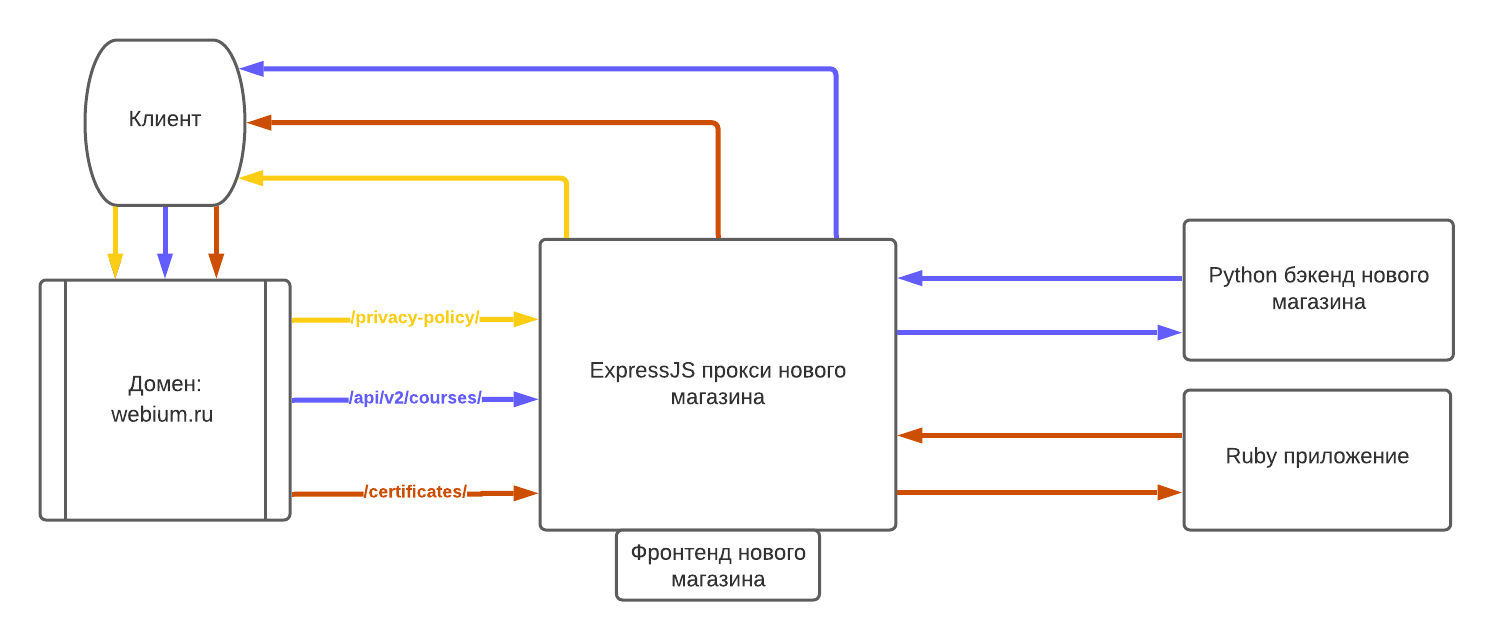
Схема маршрутизации трафика с помощью прокси на Express.js
На схеме показаны примеры 3 видов запросов:
/privacy-policy/ (желтый) — статичная страница нового магазина. Express.js обрабатывает запрос и отдает результат клиенту.
/api/v2/courses/ (синий) — запрос к новому бэкенду. Запрос проксируется в новый Python-бэкенд, результат отдается клиенту.
/certificates/ (красный) — страница из LMS. Express.js приложение ничего не знает про такой путь. Запрос проксируется в Ruby-приложение, результат отдается клиенту.
Запуск
Запуск новой большой системы – всегда риск. Особенно когда система напрямую отвечает за продажи.
Мы запускались в преддверии старта продаж Весеннего Фреша – второго по важности и прибыли курса Вебиума. Сломать флоу оплаты на старте совершенно неприемлемо — один день простоя стоит миллионы рублей. Упускать выгоду от запуска корзины удобной оплатой и классной системой скидок тоже не вариант — бизнес у Вебиума сезонный.
Поэтому мы заранее тщательно проработали план отката: заполнили все необходимые для продаж данные и в новом магазине, и в старой системе. Подготовили фиче-флаги — переменные окружения, переключение которых моментально вернёт старую систему в строй.
До Вебиума у нас был опыт большого перезапуска Сноба. Cноб нам пришлось откатывать три раза — поэтому мы подготовились по полной.
Чеклист запуска. Мы подготавливаем чеклисты к каждому запуску нового продукта.
После запуска в техподдержку одно за другим стали поступать сообщения о проблемах с аутентификацией. Мы уже готовы были жать на кнопку отката, но перед этим посмотрели аналитику. Выяснилось, что с проблемами сталкивается совсем небольшой процент пользователей — в основном те, у кого в старой системе было несколько учетных записей. Вместо отката мы быстро починили самые серьёзные проблемы, а по сложным кейсам составили инструкцию для техподдержки.
Ни один пользователь не столкнулся с проблемами непосредственно во процессе оплаты – все, кто хотели заплатить Вебиуму деньги, смогли это сделать. Мы этим гордимся.
Запуск состоялся. Дальше мы чинили обнаруженные баги, доделывали оставшиеся фичи и передавали разработку магазина Никите Савостину — новому техническому директору Вебиума, которого помогли нанять параллельно с разработкой.
Часть вторая: Перезапуск LMS. Март - сентябрь 2022
После запуска магазина перед нами стояла задача перезапустить LMS – платформу, где ученики смотрят вебинары, решают задания и общаются с наставниками.
Вместе с LMS нужно было перезапустить админку для сотрудников. В магазине мы смогли обойтись стандартной Django-админкой — ей пользуются контент-менеджеры когда нужно обновить цены, создать промокод или обновить маркетинговые лендинги. Для LMS так не пойдёт — в админку заходят сотни сотрудников каждый день: распределяют учеников по группам, редактируют расписание, проверяют домашние задания и общаются с учениками.
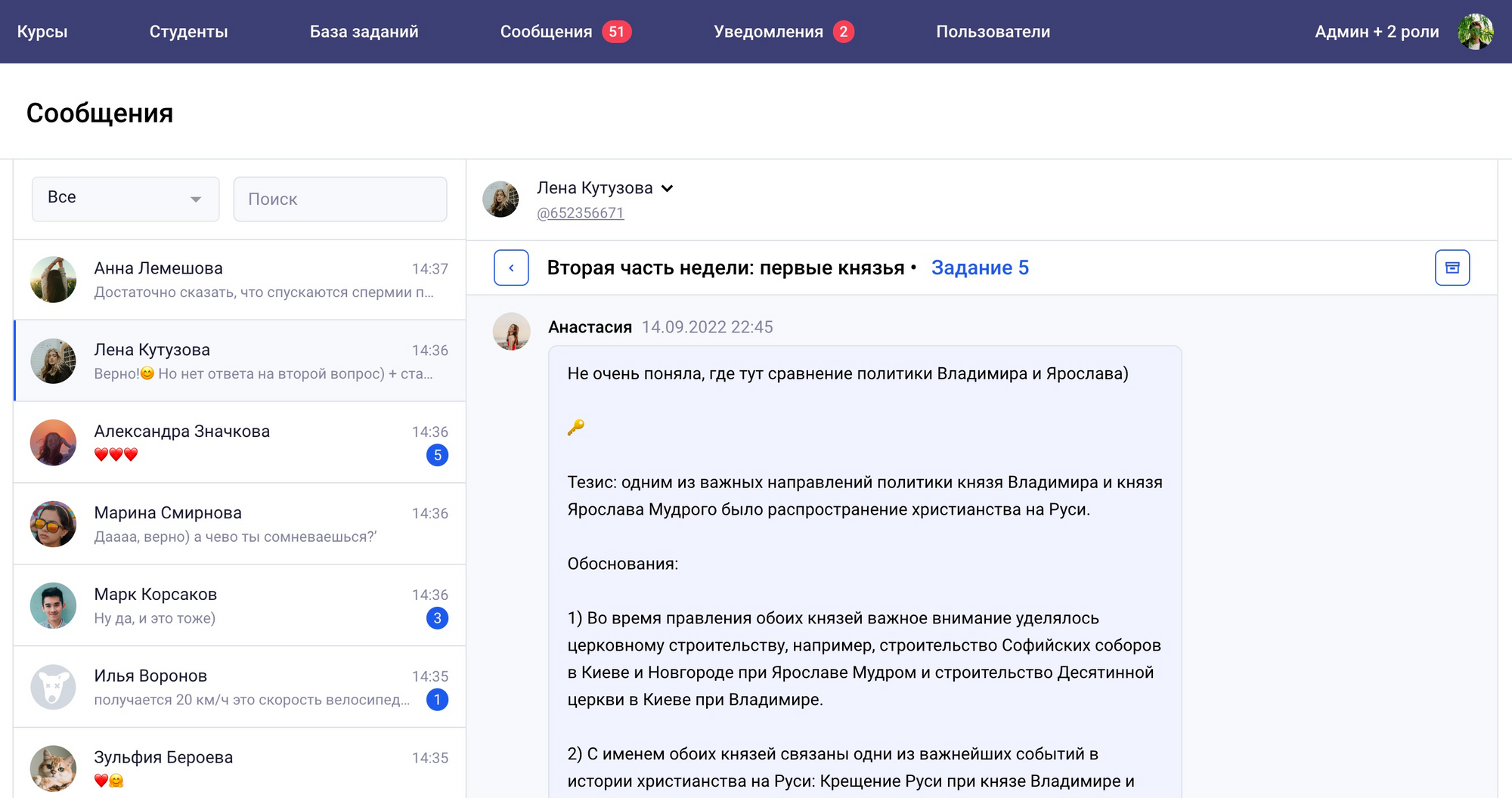
Интерфейс общения учеников и наставников — у каждого решенного задания своё обсуждение
При разработке LMS и админки мы столкнулись с новыми вызовами. С одной стороны, для LMS нужно меньше интеграций с внешними сервисами — не нужно принимать платежи и отправлять информацию в бухгалтерские сервисы или интегрироваться с легаси-системой, которую разрабатывает другая команда. С другой стороны, LMS сложнее — в магазине всё строится вокруг одного большого сценария продажи курсов ученикам, а в LMS одно перечисление сценариев занимает 7 страниц в договоре. Всего сценарии можно разделить на 5 групп:
Работа с курсами, расписанием занятий и календарём, отдельно для учеников и для наставников.
Автоматическое и ручное распределение учеников по группам.
Учебный контент: просмотр вебинаров и уроков, решение и проверка заданий.
Просмотр и рассылка уведомлений на сайте и в VK для учеников и сотрудников.
Чаты с обсуждением заданий: отдельно для учеников и наствников.
В магазине все пользователи одинаковые — это ученики. В админке LMS куча разных людей: контент-менеджеры, наставники, управляющие домашними заданиями, преподаватели предметов и супер-админы. У всех свои права и ограничения.
Так выглядит страница курса у ученика
Архитектура
Когда мы делали магазин, мы сразу думали про новую LMS. Со стороны магазина ничего не менялось – он по прежнему складывает события в RabbitMQ и не думает, какая LMS их потребляет: новая или старая.
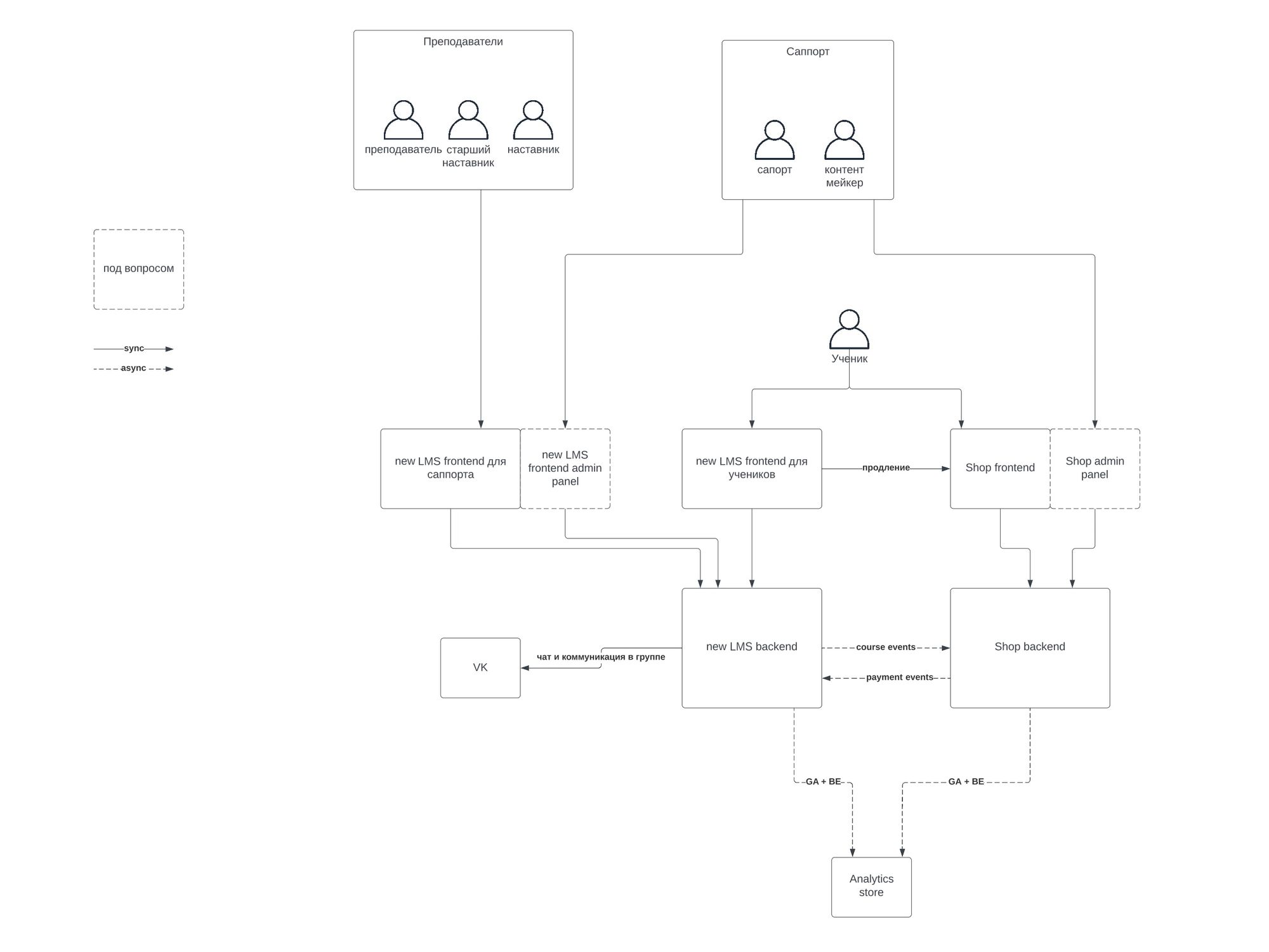
Высокоуровневая архитектура нового Вебиума из архитектурной документации, которую мы передали вместе с проектом
С точки зрения архитектуры LMS разделена на следующие элементы:
Курсы и их жизненный цикл
Распределение учеников по группам
Аутентификация и авторизация и управление ролями сотрудников
Аутентификация и авторизация учеников
Уведомления
Учебный контент
Чаты наставников и учеников
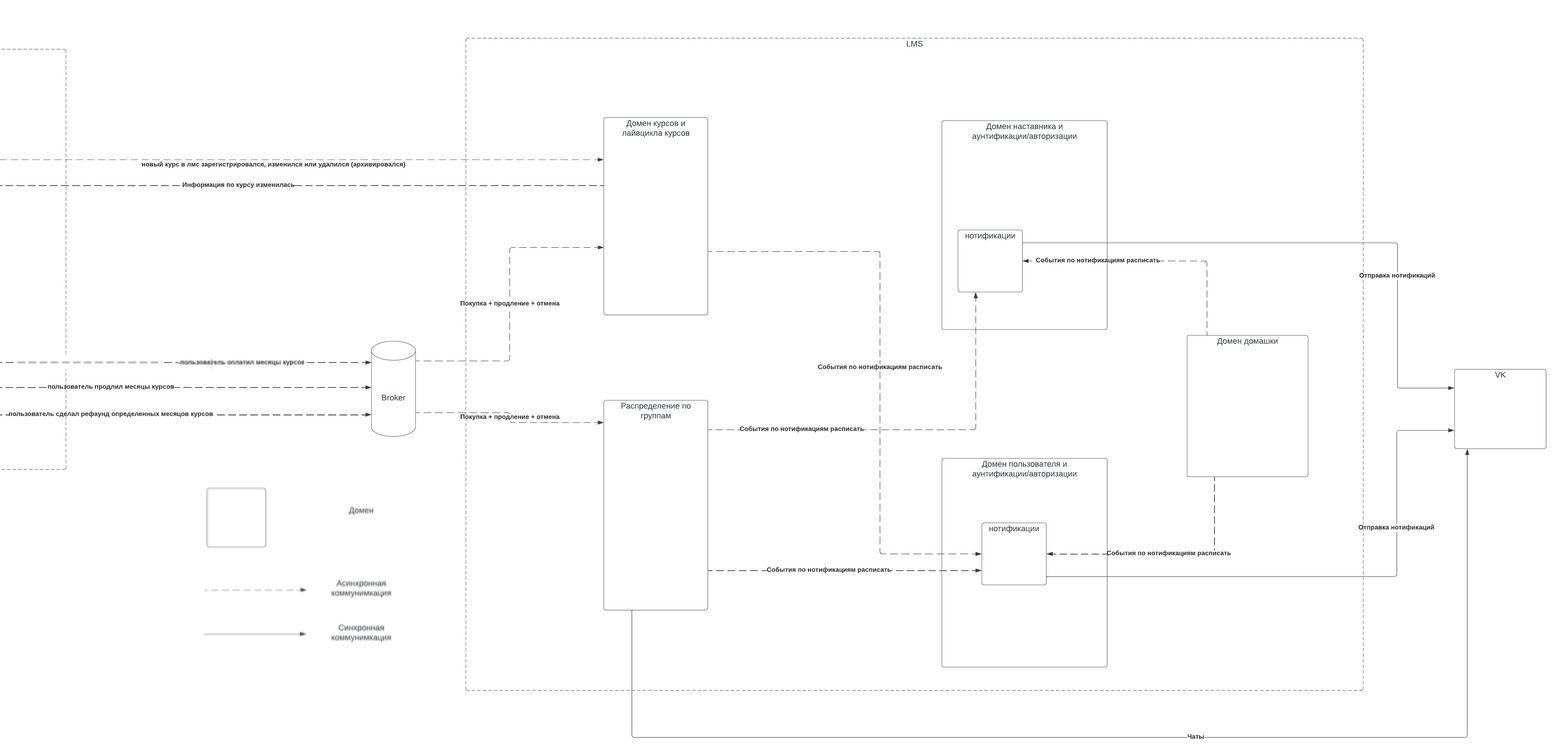
Про каждый их них можно написать отдельную статью. Покажем немного внутренней кухни: ниже схема коммуникации между ключевыми элементами LMS. Картинка взята из внутренней документации — показываем без прикрас.
Коммуникация между ключевыми элементами LMS. Стрелки в левой части ведут из магазина.
Инфраструктура
Код нового Вебиума хранится в 6 репозиториях:
Бэкенд магазина
Фронтенд магазина
Бэкенд LMS и админки LMS
Фронтенд LMS
Фронтенд админки LMS
Инфраструктура
Мы полностью разделяем кодовые базы магазина и LMS. Это даёт гибкость — нам не нужно учитывать маркетинговые фичи в сущностях учебного процесса и наоборот. В старой системе такого разделения не было — это мешало быстро тестировать продуктовые гипотезы.
Мы храним бэкенд LMS и админки в одном репозитории, а фронтенды — в разных. Бэкенд общий, потому что данные довольно сильно размазаны между системами. К примеру, с точки зрения бэкенда домашнее задание, которое решает ученик и проверяет наставник — одна и та же сущность. Фронтенды отдельные, потому что с точки зрения интерфейса решение домашки и её проверка — совершенно разные сценарии. У фронтенда LMS и админки разные дизайн-системы, разные пользователи, разные требования к качеству интерфейса и оптимизации.
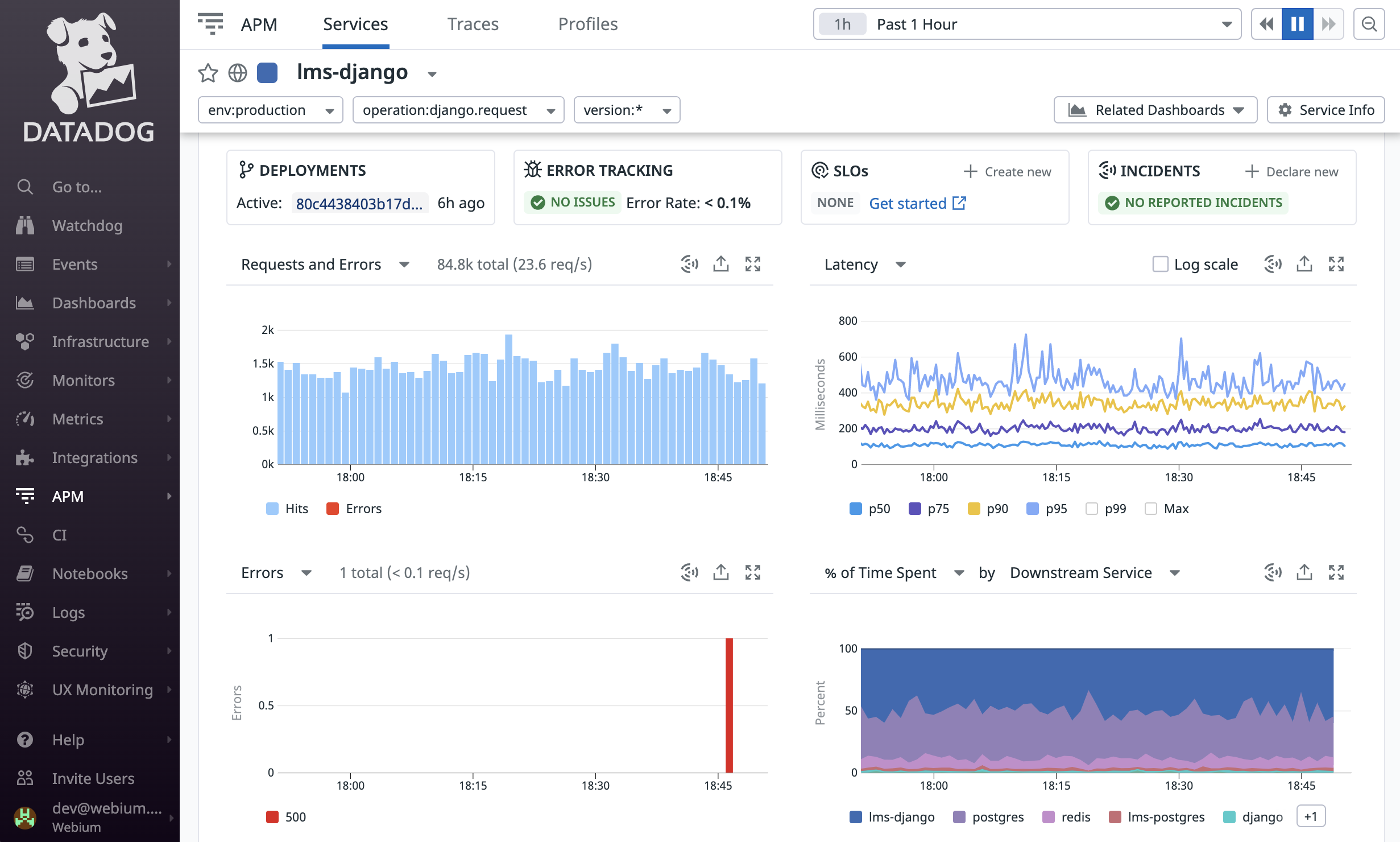
Для мониторинга и трекинга ошибок мы используем проверенные инструменты — Datadog и Sentry. Для CI/CD впервые использовали GitHub Actions (раньше использовали Circle) и остались довольны.
Мониторинг в Datadog
Запуск LMS
Как и в случае с магазином, нам нужно было интегрировать новую систему с существующей. На запуске магазина нужно было интегрироваться со старой LMS, на запуске LMS — с новым магазином. Конечно, второй случай — проще: обе системы мы сделали сами.
lms.webium.ru — сайт LMS. До запуска там была старая LMS, после запуска — новая.
Админка LMS.
Запасной домен, на который переедет старая LMS после запуска.
С админкой LMS всё просто — сайт просто нужно включить.
Перенос LMS для учеников мы разбили на 2 этапа. На этом этапе перенесли старую систему на отдельный домен. На основном домене LMS включили новую систему, но она редиректила все запросы на старый. С точки зрения инфраструктуры работала новая LMS, а с точки зрения продукта и пользователя — старая. Это позволило нам отловить баги инфраструктуры и старой системы, в которой местами был захардкожен адрес. Когда все баги отловили — мы просто выключили редирект и ученики попали в новую систему.
Разделение на этапы помогло нам снизить количество действий и суету на запуске. Базовые проблемы с инфраструктурой и проблемы продуктом можно было решать в разное время. Ну и конечно, мы добавили себе ментального спокойствия — когда есть возможность откатиться назад одной командой, чувствуешь себя гораздо увереннее.
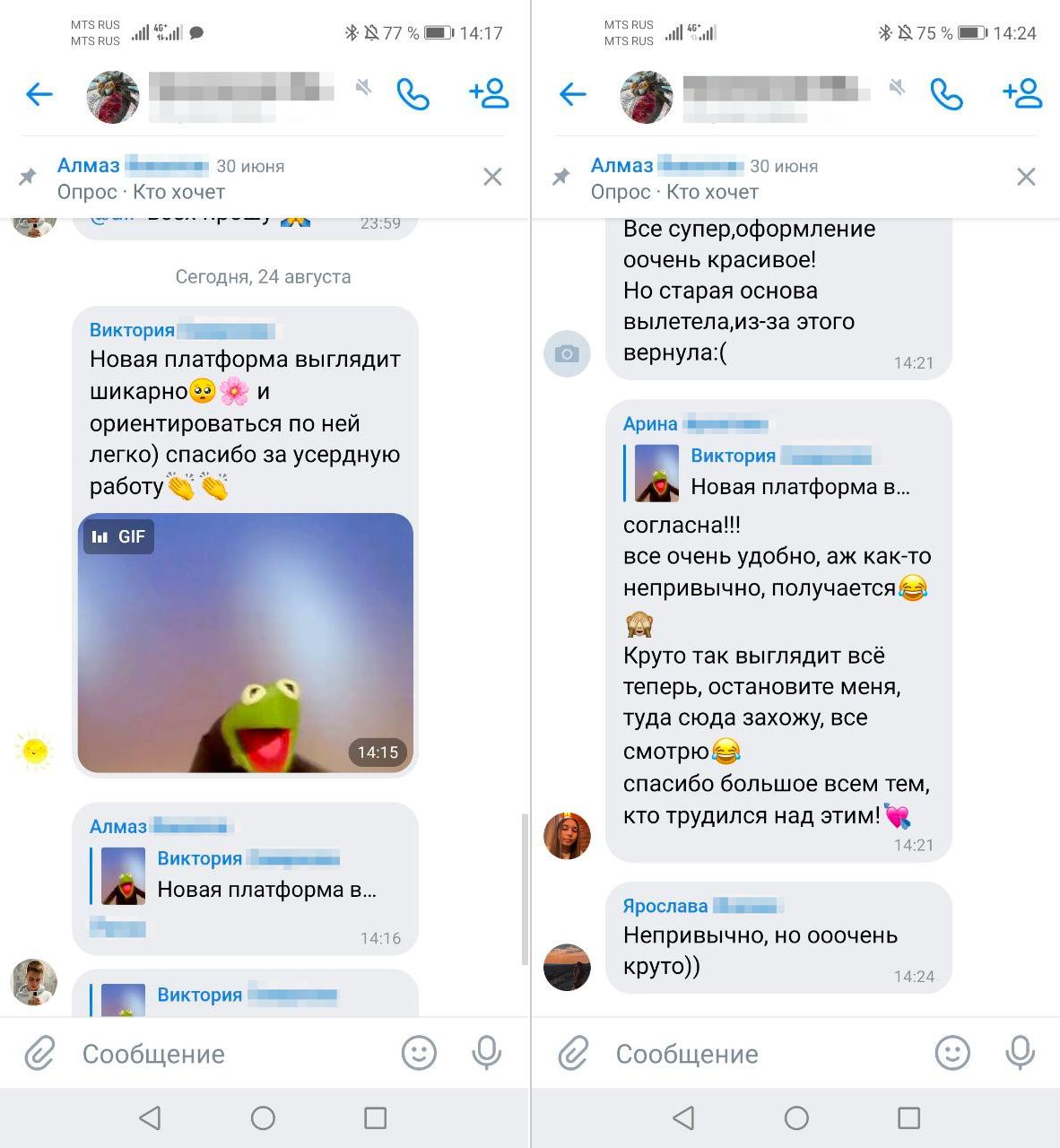
Мы настолько дотошно подготовились к продакшену, что запуск получился очень спокойным. Вот такую обратную связь оставляли ученики в чатах Вебиума.
Обратная связь от учеников в день запуска
Конечно потом вылезли проблемы — где-то не хватало фич для критичных процессов, какие-то части системы падали от нагрузки. В течение месяца после запуска мы исправили все эти проблемы.
Что дальше
За год мы перезапустили всю техническую платформу Вебиума без остановки учебного процесса. Теперь у бизнеса есть возможность бодро тестировать новые продуктовые гипотезы, а по прозрачной аналитике видно, в какие из них стоит вкладываться.
За время перезапуска Вебиум с нашей помощью нанял технического директора и построил внутреннюю команду разработки. Ребята программировали платформу бок о бок с нами, теперь они будут развивать уже знакомую им систему дальше.
Сейчас у Вебиума есть не только классные руководители, маркетологи, продакты, проджекты, дизайнеры, наставники и преподаватели, но и классные программисты. А мы очень гордимся проделанной работой. И готовы двигаться дальше.
Команда
Никита Алешников, бэкенд-разработчик Андрей Бацунов, фронтенд-разработчик Алексей Богословский, фулстек-разработчик Фёдор Борщёв, технический директор Тимур Брачков, фронтенд-разработчик Михаил Бурмистров, ведущий фронтенд-разработчик, руководитель проекта Самат Галимов, технический директор Антон Давыдов, архитектор Николай Кирьянов, бэкенд-разработчик Никита Лазаренко, бэкенд-разработчик Вячеслав Набатчиков, бэкенд-разработчик Александр Нестеров, фронтенд-разработчик Ксения Сафронова, менеджер проекта Эдуард Степанов, бэкенд-разработчик Владимир Тарановский, фронтенд-разработчик Алексей Чудин, ведущий бэкенд-разработчик
Вебиум — наш заказчик: Роксана Боровик, генеральный директор Виктория Гармаш, продакт-менеджер Никита Савостин, технический директор Александр Евграфов, арт-директор Алина Тупикова, продуктовый дизайнер Богдан Пилявец, ведущий аналитик Андрей Алейников, аналитик Михаил Герун, менеджер проекта Евгений Новиков, менеджер проекта Кирилл Стариков, фронтенд-разработчик Сергей Волков, фронтенд-разработчик Елена Микиртумова, верстальщица Роман Ковалев, ведущий SEO-специалист Ольга Рокоссовская, техподдержка и тестирование Катерина Климова, техподдержка и тестирование Павел Романов, технический директор на этапе подготовки перезапуска Евгений Юрьев, разработчик legacy-системы Илья Конаныхин, разработчик legacy-системы Михаил Сахно, бэкенд-разработчик