DevEx в Django — 2 часа лайвкодинга
Ребята с PiterPy выложили двухчасовой сеанс лайвкодинга, где я 2 часа (!) вживую (!) делаю проект на Django, в котором кайфово:
Фёдор Борщёв
Ребята с PiterPy выложили двухчасовой сеанс лайвкодинга, где я 2 часа (!) вживую (!) делаю проект на Django, в котором кайфово:
Этот доклад я рассказывал в 2021 году, но в 2023 всё ещё ничего не изменилось: Django — по-прежнему лучший инструмент для веб-бекенда в Python, если не пытаться тащить в неё батарейки и генерить на ней HTML.
Вебиум — онлайн-школа для подготовки к ЕГЭ. 30 тысяч школьников, тысяча наставников, 20 тысяч вопросов и 2 тысячи домашних заданий на сотни тем.
В 2021 году у Вебиума уже была рабочая система на Ruby, которую разрабатывали подрядчики-аутcорсеры. К нам они обратились с привычной проблемой — подрядчики медленно пилят фичи. Посмотрев код и оценив возможности команды, мы поняли, что рефакторить существующий код — долго и дорого, и решили перезапустить систему своими руками на привычном стеке — Django и Nuxt.js. Справились за год: с сентября 2022 все ученики покупают и проходят курсы в новой системе.
Перед нами стояли 3 задачи:

Дедлайн всего проекта — сентябрь 2022. Министерство образования не станет переносить ЕГЭ из-за того, что мы не успели доделать, например, отправку уведомлений в VK.
Чтобы не подписываться сразу на гигантский годовой проект, мы разбили работу на 2 больших этапа — запуск нового магазина и запуск новой платформы обучения (Learning Management System, LMS). Магазин – часть сайта, где школьники и родители покупают курсы. В LMS школьники учатся: смотрят вебинары и учебные материалы, решают задания и общаются с наставниками.
Благодаря такому разделению мы смогли запустить магазин не дожидаясь разработки новой LMS. Но есть и сложность — пришлось подружить новый магазин со старой LMS, которую разрабатывает чужая команда.
Перезапуск магазина давал два ключевых профита бизнесу: корзину и прозрачную аналитику. В старом Вебиуме было серьёзное продуктовое ограничение — можно было купить только один курс в одном чеке. Хочешь второй курс — проходи всю корзину ещё раз. Это плохо и для бизнеса и для учеников. Для бизнеса — это низкий средний чек, а для учеников это ухудшает качество наших услуг — ни один ВУЗ не принимает студентов по результатам только одного предмета. Технический ВУЗ может требовать информатику и математику, фармацевтический — химию и биологию, и почти везде требуется русский язык.
Нам нужно было сделать удобную корзину: с возможностью купить сразу пачку курсов и получить за это скидку. А ещё в старой системе было плохо с аналитикой — нам нужно было сделать структуру данных, которая не вызывает желания постричься в монахи. Серьёзно — посчитать важные для бизнеса показатели вроде выручки или количества проданных месяцев на старой системе стоило несколько дней ручной работы, потому что эта информация хранилась в JSON-ах с разнородным форматом.
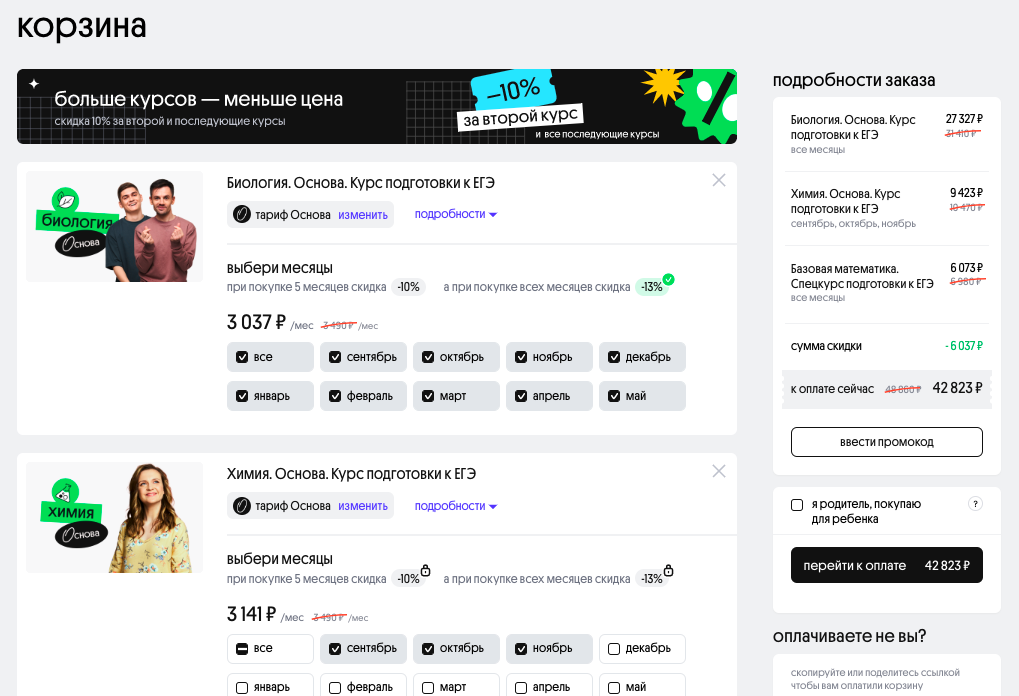
Мы сделали две системы: наш магазин отвечал за продажи курсов, а обучение мы оставили в старом монолите на Ruby. Конечно, у каждой системы мы сделали отдельную БД — если бы мы переиспользовали старую, то притащили бы все болячки аналитики.
При переносе пользователей заметили отклонение от правила Парето — мы перенесли 99% (!) пользователей и считали свою работу успешной. Но выяснилось, что 1% оставшихся пользователей делали у нас кучу заказов, и они настолько важны для бизнеса, что без них задачу нельзя было считать решённой. На перенос этого 1 золотого % у нас ушло больше времени, чем на 99% остальных!
Система, которая как-то работает, у Вебиума уже была. Перед нами стояла задача сделать систему, которую будет удобно поддерживать и развивать будущей ин-хаус команде Вебиума. Новая система получалась сложной, поэтому мы с самого начали наняли Антона Давыдова на роль архитектора. Он разобрался в деталях бизнеса и спроектировал основные составляющие системы ещё до того, как мы написали первую строчку кода, а самое главное — оставил понятную документацию, которая сильно ускоряет погружение новых программистов в работу над Вебиумом даже после нашего ухода.
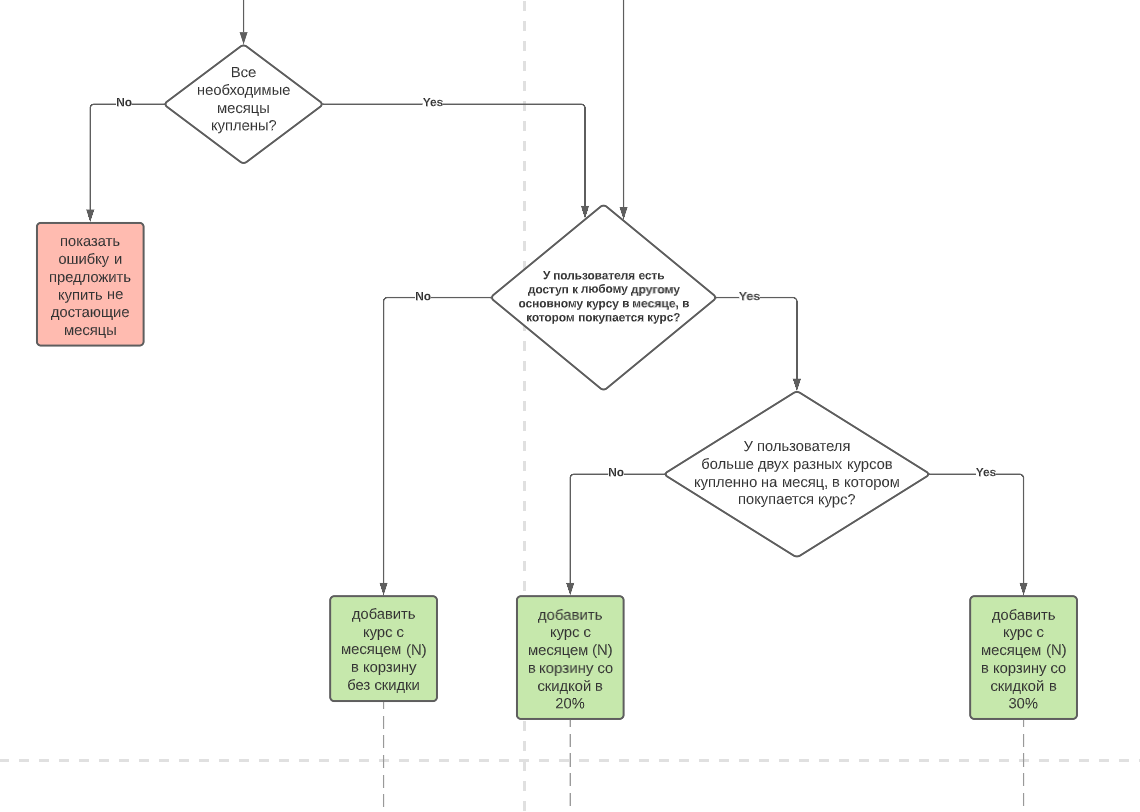
У старой и новой системы 2 ключевые точки соприкосновения: пользователи и покупки. Для пользователей мы придумали однонаправленный поток данных с новым магазином в качестве источника правды. Регистрация и изменение пользователей происходит на стороне магазина. События об изменениях стримятся в старую LMS. Если студент заходит на страые страницы управления профилем в LMS — мы его редиректим на магазин.
Открытие доступов к курсам тоже работает однонаправленно: при покупке курса в новом магазине создается событие, в ответ на которое старая LMS открывает доступ студенту. Отправка событий построена на RabbitMQ.
Для маршрутизации трафика мы использовали уже проверенную на Снобе комбинацию из traefik и Express.js. Express.js выполняет роль BFF (Backend for Frontend). Это быстрый прокси-сервер, у которого несколько важных функций:
Все неизвестные пути Express.js направляет на обработку в legacy-систему. Если после запуска нужно откатиться на старую систему — мы просто отключаем прокси. Старая система продолжает работать как ни в чём не бывало.
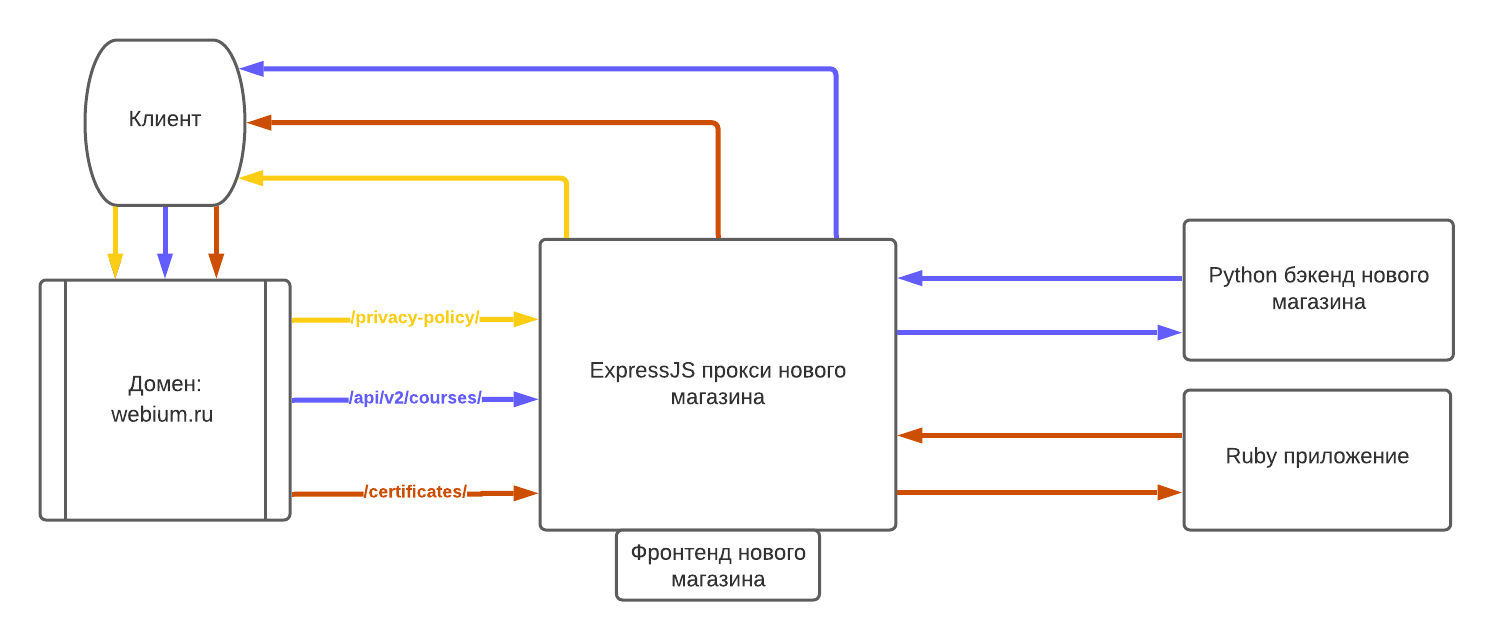
На схеме показаны примеры 3 видов запросов:
Запуск новой большой системы – всегда риск. Особенно когда система напрямую отвечает за продажи.

Мы запускались в преддверии старта продаж Весеннего Фреша – второго по важности и прибыли курса Вебиума. Сломать флоу оплаты на старте совершенно неприемлемо — один день простоя стоит миллионы рублей. Упускать выгоду от запуска корзины удобной оплатой и классной системой скидок тоже не вариант — бизнес у Вебиума сезонный.
Поэтому мы заранее тщательно проработали план отката: заполнили все необходимые для продаж данные и в новом магазине, и в старой системе. Подготовили фиче-флаги — переменные окружения, переключение которых моментально вернёт старую систему в строй.
До Вебиума у нас был опыт большого перезапуска Сноба. Cноб нам пришлось откатывать три раза — поэтому мы подготовились по полной.

После запуска в техподдержку одно за другим стали поступать сообщения о проблемах с аутентификацией. Мы уже готовы были жать на кнопку отката, но перед этим посмотрели аналитику. Выяснилось, что с проблемами сталкивается совсем небольшой процент пользователей — в основном те, у кого в старой системе было несколько учетных записей. Вместо отката мы быстро починили самые серьёзные проблемы, а по сложным кейсам составили инструкцию для техподдержки.
Ни один пользователь не столкнулся с проблемами непосредственно во процессе оплаты – все, кто хотели заплатить Вебиуму деньги, смогли это сделать. Мы этим гордимся.
Запуск состоялся. Дальше мы чинили обнаруженные баги, доделывали оставшиеся фичи и передавали разработку магазина Никите Савостину — новому техническому директору Вебиума, которого помогли нанять параллельно с разработкой.
После запуска магазина перед нами стояла задача перезапустить LMS – платформу, где ученики смотрят вебинары, решают задания и общаются с наставниками.
Вместе с LMS нужно было перезапустить админку для сотрудников. В магазине мы смогли обойтись стандартной Django-админкой — ей пользуются контент-менеджеры когда нужно обновить цены, создать промокод или обновить маркетинговые лендинги. Для LMS так не пойдёт — в админку заходят сотни сотрудников каждый день: распределяют учеников по группам, редактируют расписание, проверяют домашние задания и общаются с учениками.
При разработке LMS и админки мы столкнулись с новыми вызовами. С одной стороны, для LMS нужно меньше интеграций с внешними сервисами — не нужно принимать платежи и отправлять информацию в бухгалтерские сервисы или интегрироваться с легаси-системой, которую разрабатывает другая команда. С другой стороны, LMS сложнее — в магазине всё строится вокруг одного большого сценария продажи курсов ученикам, а в LMS одно перечисление сценариев занимает 7 страниц в договоре. Всего сценарии можно разделить на 5 групп:
В магазине все пользователи одинаковые — это ученики. В админке LMS куча разных людей: контент-менеджеры, наставники, управляющие домашними заданиями, преподаватели предметов и супер-админы. У всех свои права и ограничения.
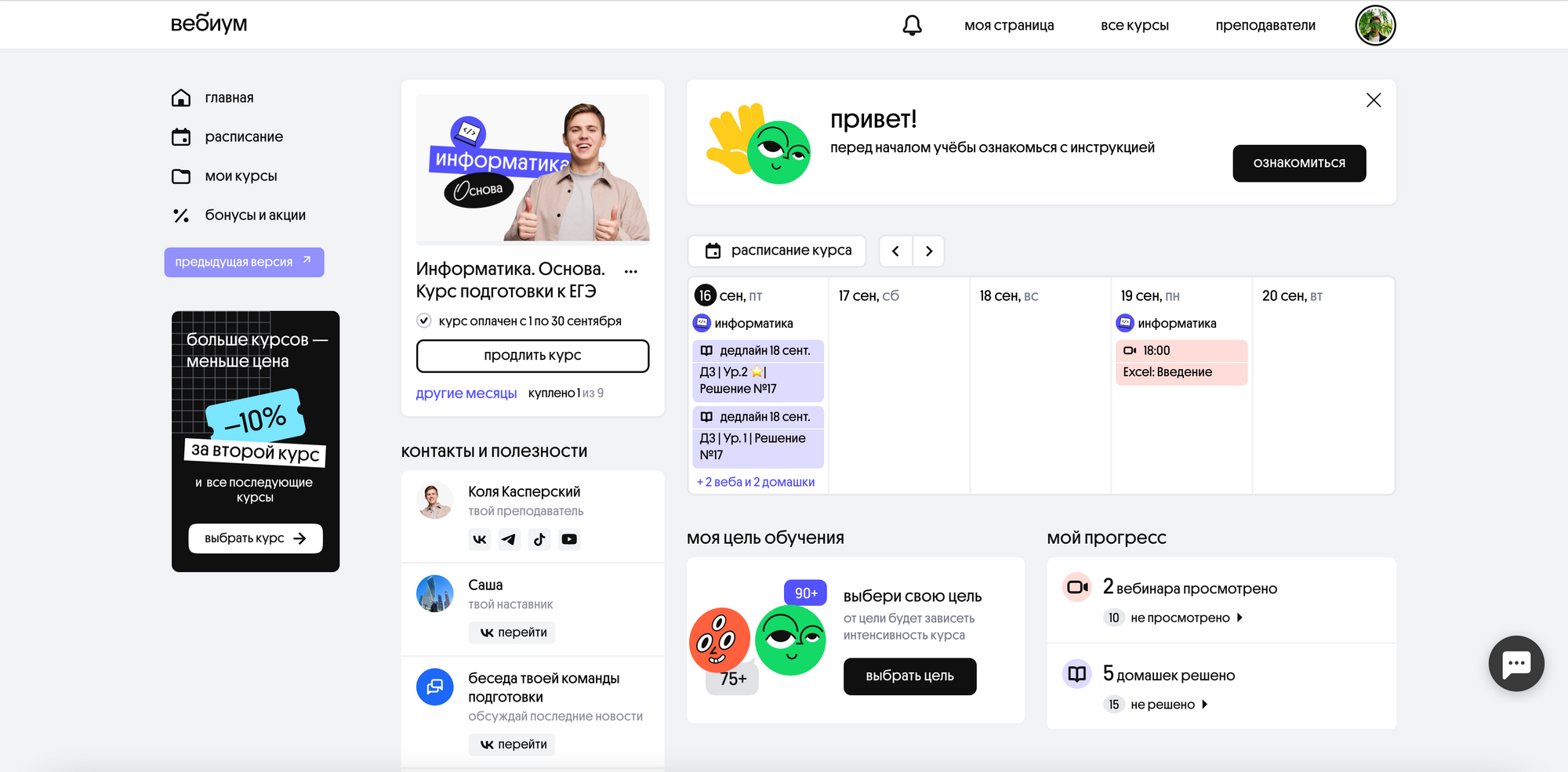
Когда мы делали магазин, мы сразу думали про новую LMS. Со стороны магазина ничего не менялось – он по прежнему складывает события в RabbitMQ и не думает, какая LMS их потребляет: новая или старая.
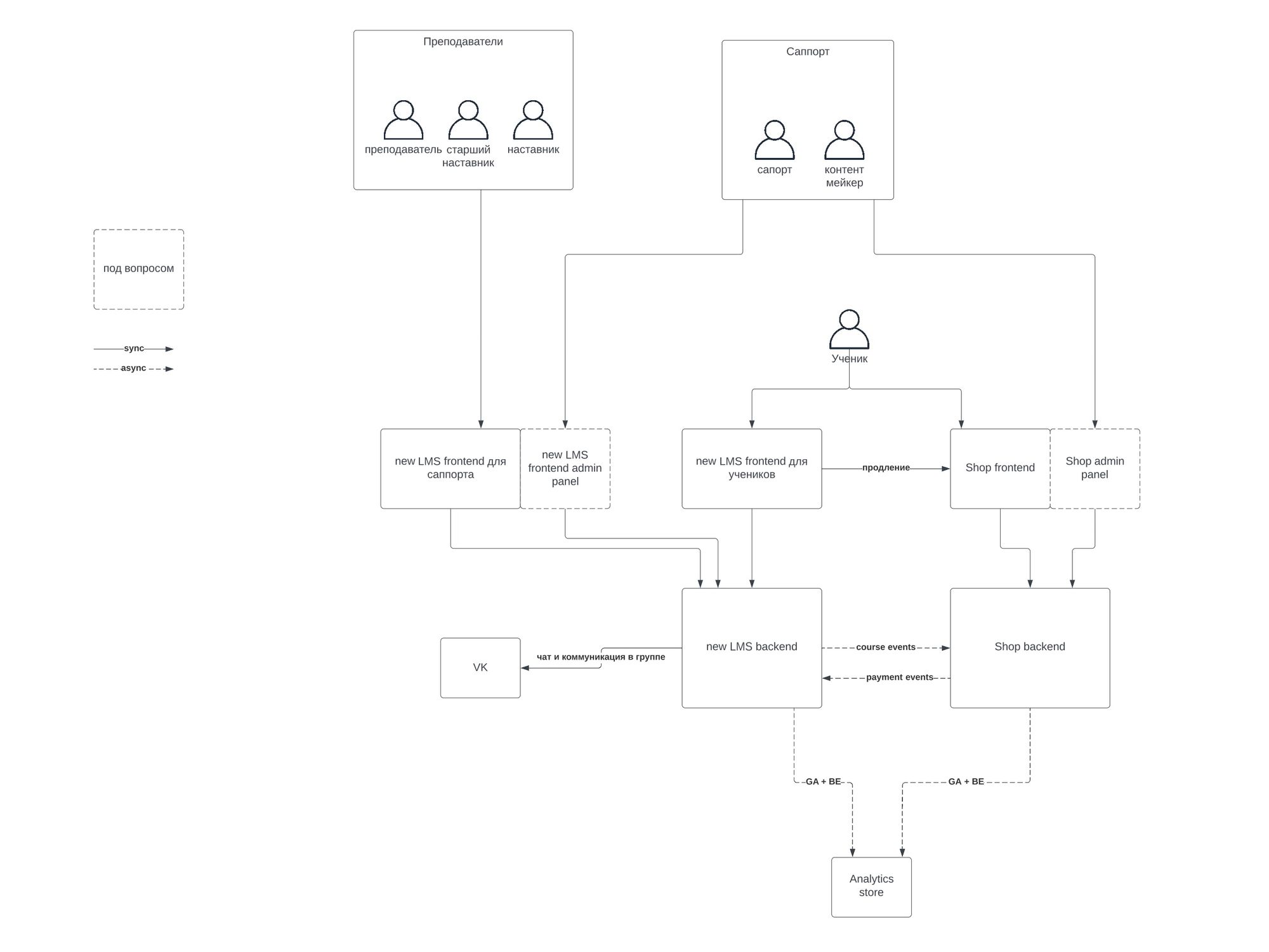
С точки зрения архитектуры LMS разделена на следующие элементы:
Про каждый их них можно написать отдельную статью. Покажем немного внутренней кухни: ниже схема коммуникации между ключевыми элементами LMS. Картинка взята из внутренней документации — показываем без прикрас.
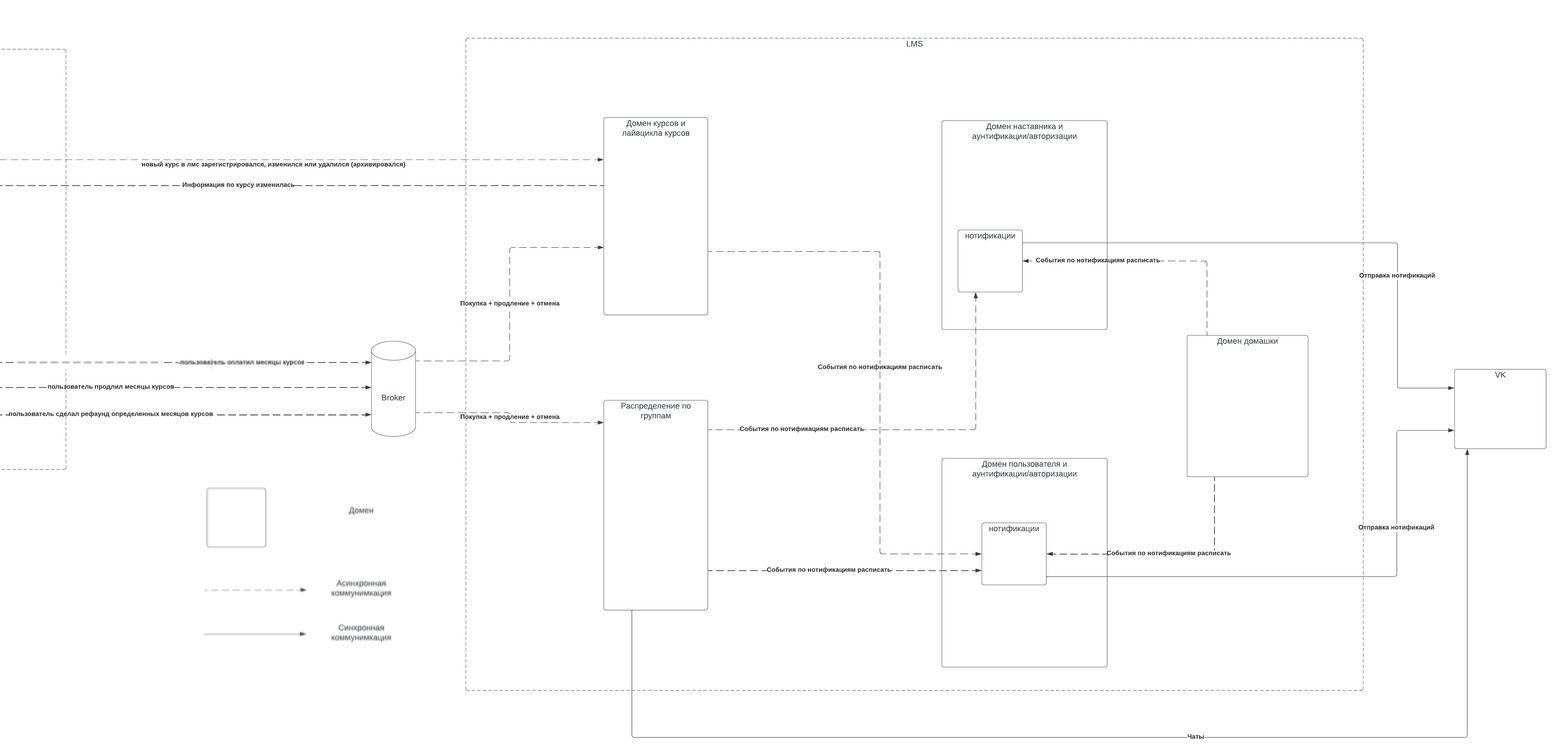
Код нового Вебиума хранится в 6 репозиториях:
Мы полностью разделяем кодовые базы магазина и LMS. Это даёт гибкость — нам не нужно учитывать маркетинговые фичи в сущностях учебного процесса и наоборот. В старой системе такого разделения не было — это мешало быстро тестировать продуктовые гипотезы.
Мы храним бэкенд LMS и админки в одном репозитории, а фронтенды — в разных. Бэкенд общий, потому что данные довольно сильно размазаны между системами. К примеру, с точки зрения бэкенда домашнее задание, которое решает ученик и проверяет наставник — одна и та же сущность. Фронтенды отдельные, потому что с точки зрения интерфейса решение домашки и её проверка — совершенно разные сценарии. У фронтенда LMS и админки разные дизайн-системы, разные пользователи, разные требования к качеству интерфейса и оптимизации.
Для мониторинга и трекинга ошибок мы используем проверенные инструменты — Datadog и Sentry. Для CI/CD впервые использовали GitHub Actions (раньше использовали Circle) и остались довольны.
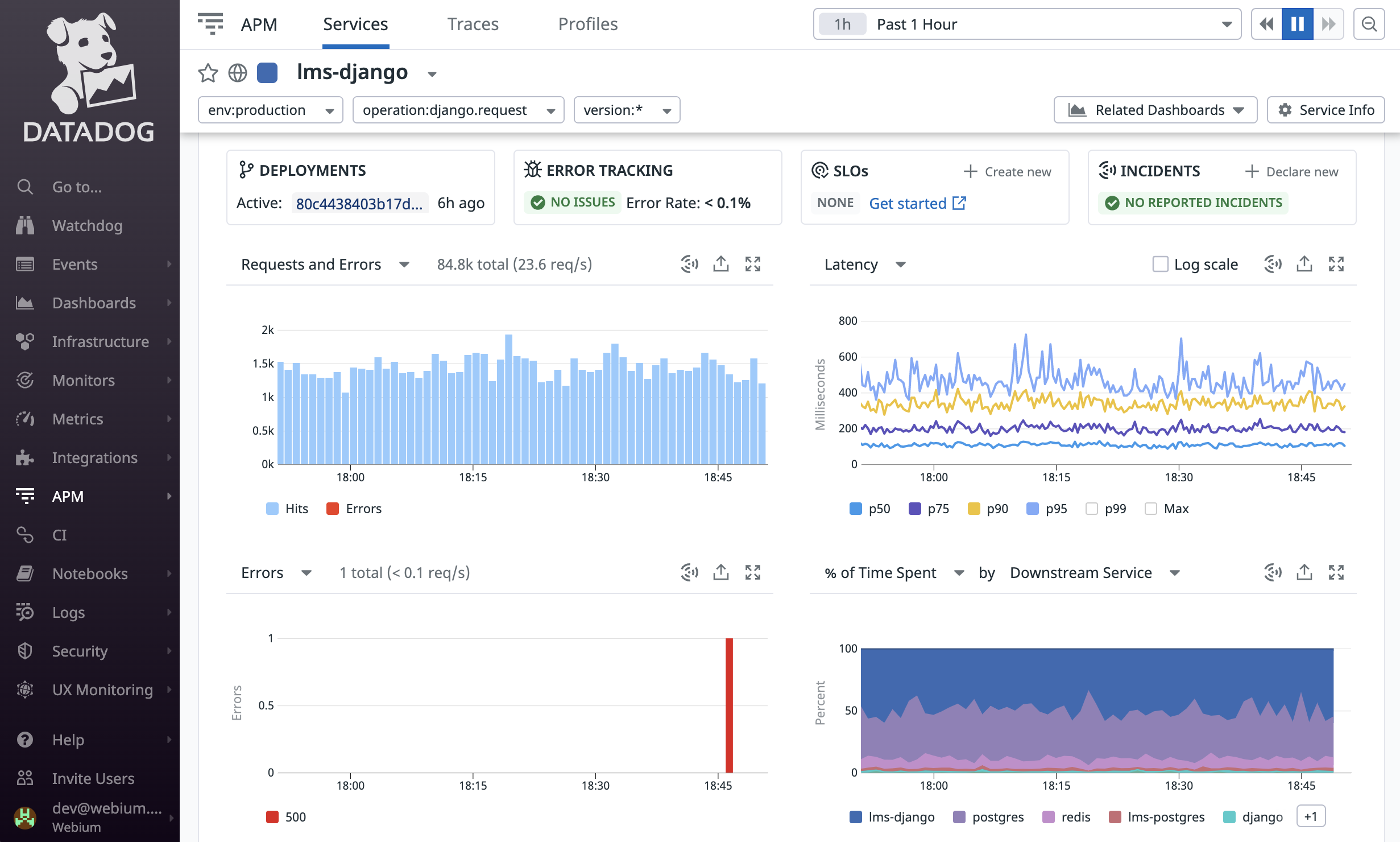
Как и в случае с магазином, нам нужно было интегрировать новую систему с существующей. На запуске магазина нужно было интегрироваться со старой LMS, на запуске LMS — с новым магазином. Конечно, второй случай — проще: обе системы мы сделали сами.
В итоге систему запускали частями
С админкой LMS всё просто — сайт просто нужно включить.
Перенос LMS для учеников мы разбили на 2 этапа. На этом этапе перенесли старую систему на отдельный домен. На основном домене LMS включили новую систему, но она редиректила все запросы на старый. С точки зрения инфраструктуры работала новая LMS, а с точки зрения продукта и пользователя — старая. Это позволило нам отловить баги инфраструктуры и старой системы, в которой местами был захардкожен адрес. Когда все баги отловили — мы просто выключили редирект и ученики попали в новую систему.
Разделение на этапы помогло нам снизить количество действий и суету на запуске. Базовые проблемы с инфраструктурой и проблемы продуктом можно было решать в разное время. Ну и конечно, мы добавили себе ментального спокойствия — когда есть возможность откатиться назад одной командой, чувствуешь себя гораздо увереннее.
Мы настолько дотошно подготовились к продакшену, что запуск получился очень спокойным. Вот такую обратную связь оставляли ученики в чатах Вебиума.
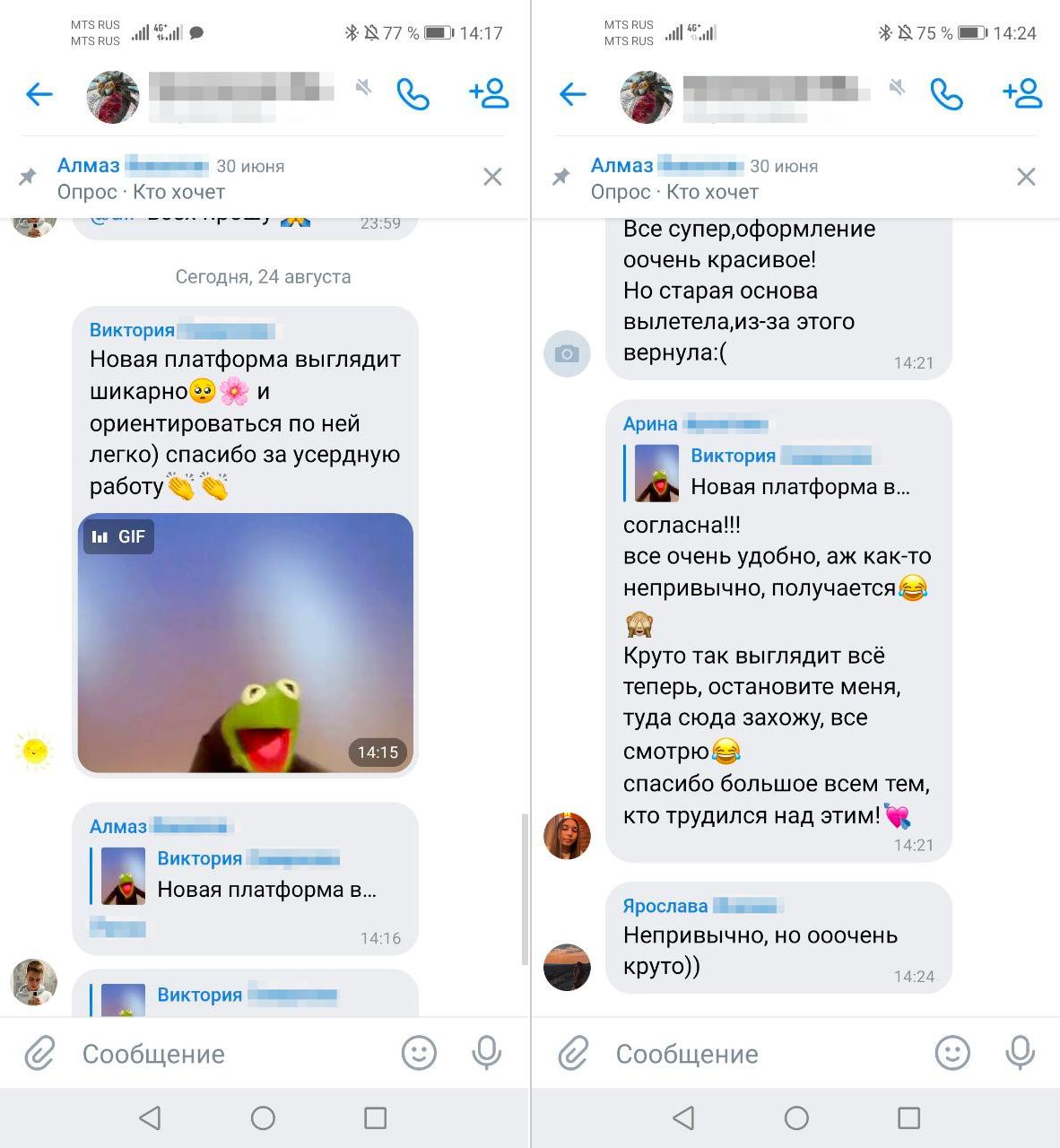
Конечно потом вылезли проблемы — где-то не хватало фич для критичных процессов, какие-то части системы падали от нагрузки. В течение месяца после запуска мы исправили все эти проблемы.
За год мы перезапустили всю техническую платформу Вебиума без остановки учебного процесса. Теперь у бизнеса есть возможность бодро тестировать новые продуктовые гипотезы, а по прозрачной аналитике видно, в какие из них стоит вкладываться.
За время перезапуска Вебиум с нашей помощью нанял технического директора и построил внутреннюю команду разработки. Ребята программировали платформу бок о бок с нами, теперь они будут развивать уже знакомую им систему дальше.
Сейчас у Вебиума есть не только классные руководители, маркетологи, продакты, проджекты, дизайнеры, наставники и преподаватели, но и классные программисты. А мы очень гордимся проделанной работой. И готовы двигаться дальше.
Никита Алешников, бэкенд-разработчик
Андрей Бацунов, фронтенд-разработчик
Алексей Богословский, фулстек-разработчик
Фёдор Борщёв, технический директор
Тимур Брачков, фронтенд-разработчик
Михаил Бурмистров, ведущий фронтенд-разработчик, руководитель проекта
Самат Галимов, технический директор
Антон Давыдов, архитектор
Николай Кирьянов, бэкенд-разработчик
Никита Лазаренко, бэкенд-разработчик
Вячеслав Набатчиков, бэкенд-разработчик
Александр Нестеров, фронтенд-разработчик
Ксения Сафронова, менеджер проекта
Эдуард Степанов, бэкенд-разработчик
Владимир Тарановский, фронтенд-разработчик
Алексей Чудин, ведущий бэкенд-разработчик
Вебиум — наш заказчик:
Роксана Боровик, генеральный директор
Виктория Гармаш, продакт-менеджер
Никита Савостин, технический директор
Александр Евграфов, арт-директор
Алина Тупикова, продуктовый дизайнер
Богдан Пилявец, ведущий аналитик
Андрей Алейников, аналитик
Михаил Герун, менеджер проекта
Евгений Новиков, менеджер проекта
Кирилл Стариков, фронтенд-разработчик
Сергей Волков, фронтенд-разработчик
Елена Микиртумова, верстальщица
Роман Ковалев, ведущий SEO-специалист
Ольга Рокоссовская, техподдержка и тестирование
Катерина Климова, техподдержка и тестирование
Павел Романов, технический директор на этапе подготовки перезапуска
Евгений Юрьев, разработчик legacy-системы
Илья Конаныхин, разработчик legacy-системы
Михаил Сахно, бэкенд-разработчик
—
Автор статьи: Михаил Бурмистров
Я выкладываю в открытом виде на гитхаб почти весь код, который пишу. Большинство — это не opensource в классическом понимании, а скорее открытая разработка, когда любой желающий может увидеть всё, что программисты обычно прячут за кучей НДА. О том, зачем мне это, я уже писал раньше. В этом посте я собрал список таких проектов, рассказав чему в них может научиться джун, пересекающийся со мной по стеку.
Стек: Django REST Framework, celery, pytest, mypy
Это Django, интегрированный с 4 платёжными системами, ОФД, сервисами транзакционнвх и маркетинговых рассылок. Внутри — лучшие практики: тысяча тестов на pytest, все известные мне плагины для flake8, CI/CD на GitHub Actions.
tough-dev-school/education-backendСтек: Ansible, Docker Swarm, PostgreSQL, MongoDB, RabbitMQ, Redis
Большой плейбук на Ansible. Внутри — 6 сервисов: бекенды, фронтенды, БД, бекапы, Metabase. Пишет логи в papertrail, создает анонимизированные дампы БД и делает еще кучу хороших практик.
tough-dev-school/infrastructureСтек: Django/vue.js(nuxt)
Когда в «Феде и Самате» мы начинаем новые проекты, мы используем готовые и преднастроенные репозитории — для django и nuxt. Это экономит время на настройке линтеров, добавлении библиотек вроде pytest или jest, нужных на всех проектах.
fandsdev/django, fandsdev/nuxt-boilerplate,Набор образов, которые помогают удобнее поддерживать небольшой продакшен на docker swarm:
Стек: python-telegram-bot, celery
Телеграм-бот для GTD-гиков вроде меня: пересылает сообщения из телеграма на почту, чтобы не терять и разбирать всё, что вам пишут. Подробности тут.
f213/selfmailbotМои дотфайлы для macos. Внутри fish, neovim, karabiner, и полный список софта, который я юзаю в виде роли Ansible. Сделано на dotbot.
f213/dotfilesСтек: python-telegram-bot, Amazon Rekognition
В 2021 году в комментах к моему каналу появилось много спамеров. Я разобрал все паттерны их поведения и написал бота, который удаляет сообщения. Идея простая — если лишить спамеров возможности увести пользователя на свой канал или страницу — спалить станет не за чем. Так, у меня в канале нельзя постить ссылки на веб или телеграмм, писать не от своего имени.
f213/channel-discussion-antispam-botСтек: Python, Scrapy
Делает RSS-ленту из моего канала в телеге. Легко переделать под любой другой канал.
f213/tg2rssНедавно мы закончили важную веху — запустили новый движок блогов на snob.ru. Задача была нетривиальной — за полгода мы перезапустили сайт высоконагруженного медиа с кучей легаси-кода. В этой заметке я расскажу, какие технологические решения мы приняли.
Сноб — это интернет-медиа, статьи в котором пишут не только штатные редакторы, но и внешние участники проекта: любой человек может приобрести подписку и завести собственную колонку на snob.ru. Коду проекта больше 10 лет, писали его разные люди на совершенно разных технологиях — в копилке есть и Zend Framework с MySQL и Django с PostgreSQL.
Нас с Саматом позвали, когда разработка была в плачевном состоянии: новые фичи уже не выкатывали, а починка одного бага приводила к появлению двух-трёх новых. Первым делом мы провели аудит: поговорили с представителями бизнеса и программистами, расковыряли исходный код и инфраструктуру. Проблемы оказались буквально везде: программисты были уставшими, инфраструктура — непрозрачной, а техдолг — огромным. Остановимся на техдолге чуть-чуть подробнее.
Проект состоит не из одного бэкенда, а из трёх: основной сайт, блоги внешних участников проекта и редакционная админка. Архитектуру взаимодействия никто не продумывал — каждую новую систему городили на предыдущие как придётся. Это привело к тому, что данные между бекендами стали передаваться совершенно непредсказуемым образом: частично через запись в базу, частично — через вебхуки. Из-за этого пользователи периодически теряют данные: если материал, профиль или комментарий не укладывается в формат обмена между системами (или в момент сохранения пролетает птичка и моргает сеть) — данные портятся.
Кроме трёх бэкендов, у проекта есть ещё три фронтенда: старый от ПХП-движка, куча кода на Django и SPA на next.js, от которого предыдущая команда успела внедрить совсем небольшие части функциональности. Сверху всего этого стоит nginx, который одним ему ведомым образом решает, какая из этих систем будет отрабатывать запрос.
Поговорив с бизнесом, мы поняли, что самая большая проблема — в ПХП-движке на Zend Framework, который обслуживает блоги участников проекта. У бизнеса есть куча гипотез, которые можно проверить, но ни одного ПХП-шинка в команде не осталось, а внешних нанять невозможно — ни один нормальный программист не пойдет работать на 10-летний легаси без здоровой инженерной культуры.
Конечно, работать дальше с таким легаси нельзя — надо как можно скорее от него избавляться. Поскольку бизнес больше всего хотел решить проблему с блогами — с них мы и начнём. Мы поставили амбициозную цель — в конце работы оставить движок, которым пользуются и блогеры, и редакция: такое уже есть у Комитета, на их «Основе» работают все сайты издательства: vc, tjournal, dtf, и редакция там пишет посты так же, как и обычные пользователи.
Решение мы начали с разработки архитектуры. В реальном мире существует только одно состояние у поста, комментария или пользователя — то, которое мы видим на экране. Проблема старой архитектуры в том, из-за ошибок проектирования это состояние в разных версиях размазано между совершенно несвязанными базами данных, и записывают его неаккуратные и несогласованные друг с другом системы. Представьте себе текст на листе бумаги, который одновременно пишут четыре первоклассника. Даже если они договорятся писать по одному слову за раз и вместе напишут связанный текст — вы никогда не поймёте, кто из них пропустил запятую или допустил смысловую ошибку.
Чтобы всегда знать, кто, зачем и когда записал данные, мы ввели единый источник правды. Пусть правдивое состояние пользователей и постов всегда находится у нас, и мы сами отвечаем за то, чтобы данные обновились в легаси-системах — транслируем все изменения в базы данных, задействуя как можно меньше старого кода. Всю синхронизацию систем друг с другом мы отрубаем — данные везде пишем только мы. Получается, что правда течёт сверху вниз, как в компонентах react.js — от нашей системы к легаси.
Экспорт данных мы построили на celery и RabbitMQ. Получилась полноценная асинхронная архитектура: все посты, которые нужно отправить в легаси, лежат в RabbitMQ, и удаляются оттуда только после того, как данные попадают во все БД. Если с трансляцией что-то пойдёт не так — мы узнаем об этом по переполненной очереди в RabbitMQ.
Инфраструктура на проекте — ещё один источник проблем. Там были разные физические серверы, конфигурация которых мутировала в течении десятилетия. ПХП-движок вообще крутился на FreeBSD — такой привет из начала 2000х! Плюс, у нас не было доступа к серверам — нельзя было даже зайти по ssh и посмотреть, что происходит.
Конечно, мы совсем не хотели делать ещё одну систему в этой непрозрачной мешанине — пара недель ушла бы только на попытки разобраться в конфигурации nginx. Решение пришло из мира фронтенда: там часто делают отдельный бекенд для фронтендеров, который который облегчает хождение в основные бекенды — маршрутизирует запросы между микросервисами, переформатирует ответы в удобный фронтенду формат, сохраняет данные авторизации — это называется BFF (Backend for Frontend). В нашем проекте уже был свой BFF — ведь нам нужно рендерить страницы на сервере, чтобы ускорить загрузку и быть понятными для поисковых роботов. Нам ничего не мешает маршрутизировать весь трафик snob.ru, включая статику через свой BFF — таким образом мы заберём полный контроль над трафиком.
Рядом с легаси-инфраструктурой мы развернули свою собственную, где на входе пользователей встречает комбинация из traefik и express.js. Теперь мы сами решаем, какая из систем обрабатывает каждый запрос — каждый новый сервис сам регистрируется в traefik и получает свою долю трафика. Если ни один сервис не хочет обрабатывать запрос — он уходит в express.js, где мы кодом решаем, обработать сервис своим фронтендом, или отдать его в легаси.
Чтобы не надорваться от нагрузки, поверх подключили Cloudflare, который раздаёт статику через свой CDN:
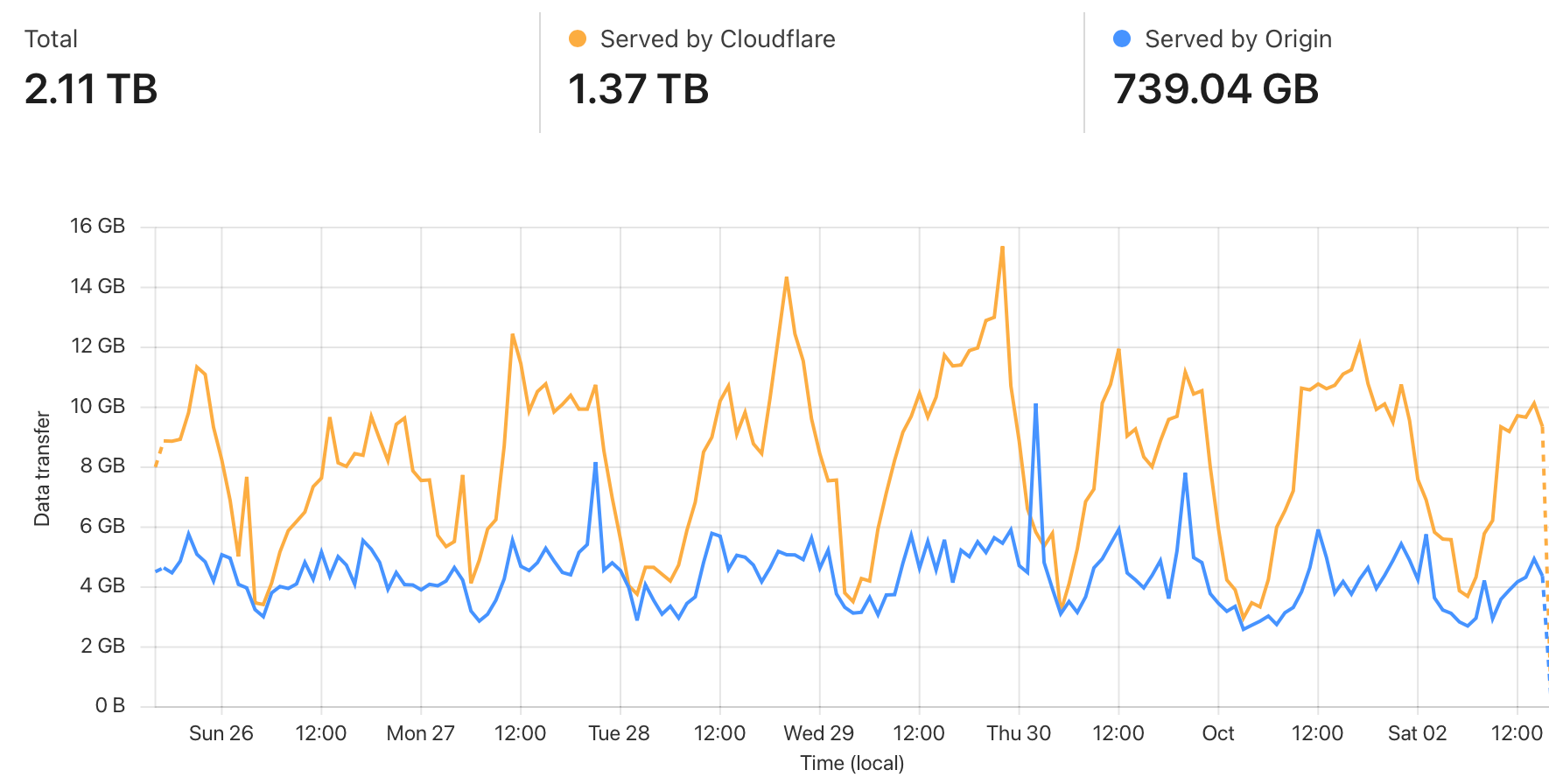
Заодно мы решили ещё одну проблему старой инфраструктуры — пропуская через себя весь трафик, мы наконец-то получили нормальную статистику происходящего в ней. Старый мониторинг строился на основе простой пинговалки в заббиксе: раз в минуту ходим в бекенд, если ответ не ок — шлём СМС админу. Чтобы понять, насколько это плохо — представьте ситуацию, в которой сайт падает от нагрузки и нормально обрабатывает только 50% пользователей. Если пинговалка попадает в ту половину пользователей, для которых сайт работает — админ об этом никогда не узнает. Наверное так же можно проверять работу ядерного реактора — если в контейнменте ничего не горит и не взрывается, значит реактор работает.
Теперь никакой пинговалки нет, а мониторинг строится на 4-х золотых сигналах — количестве запросов, времени ответа, количестве ошибок и запасу на оборудовании.
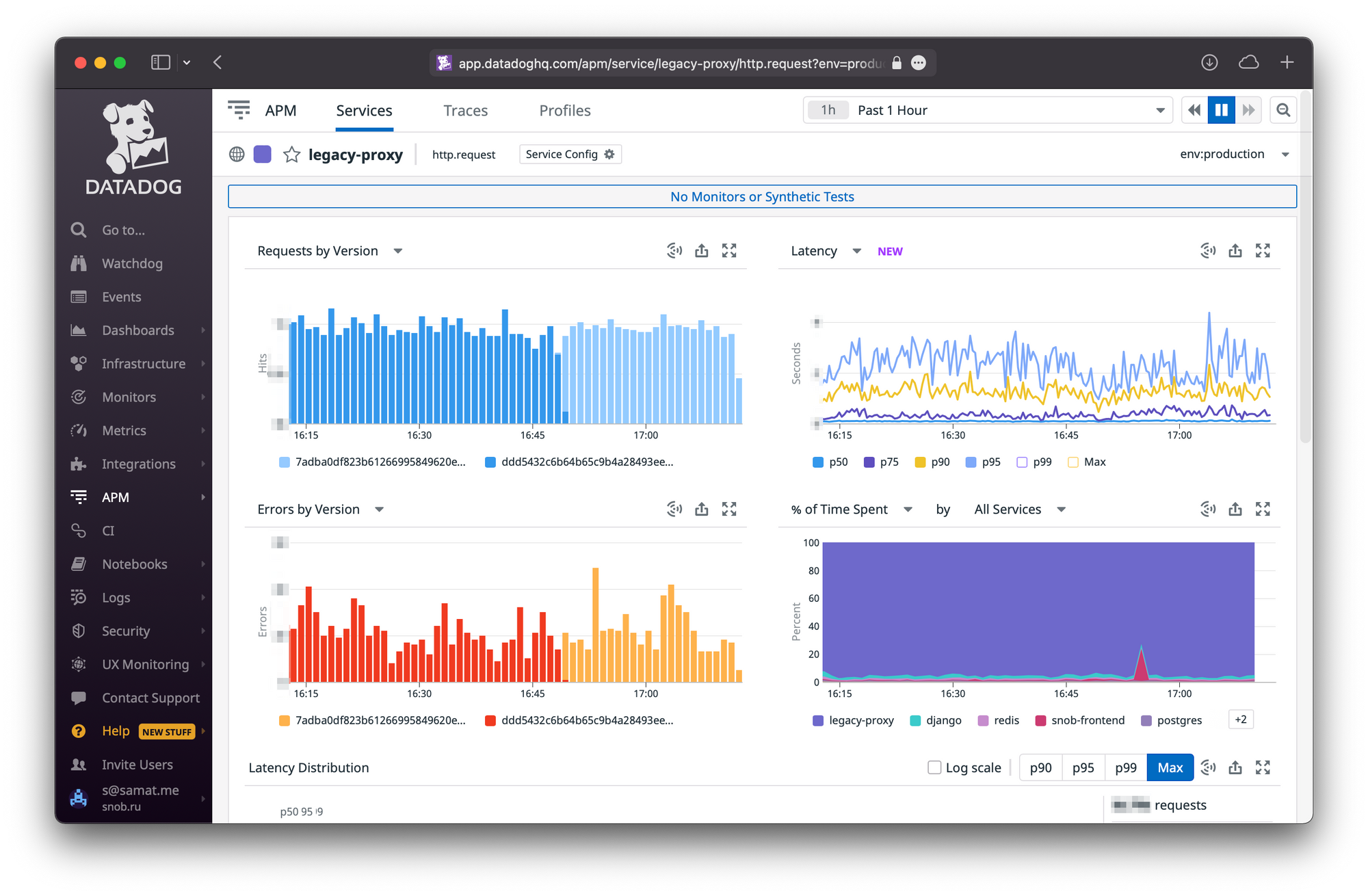
Если хоть какой-то параметр выходит из строя, робот на основе машинного обучения шлёт нам алёрт.
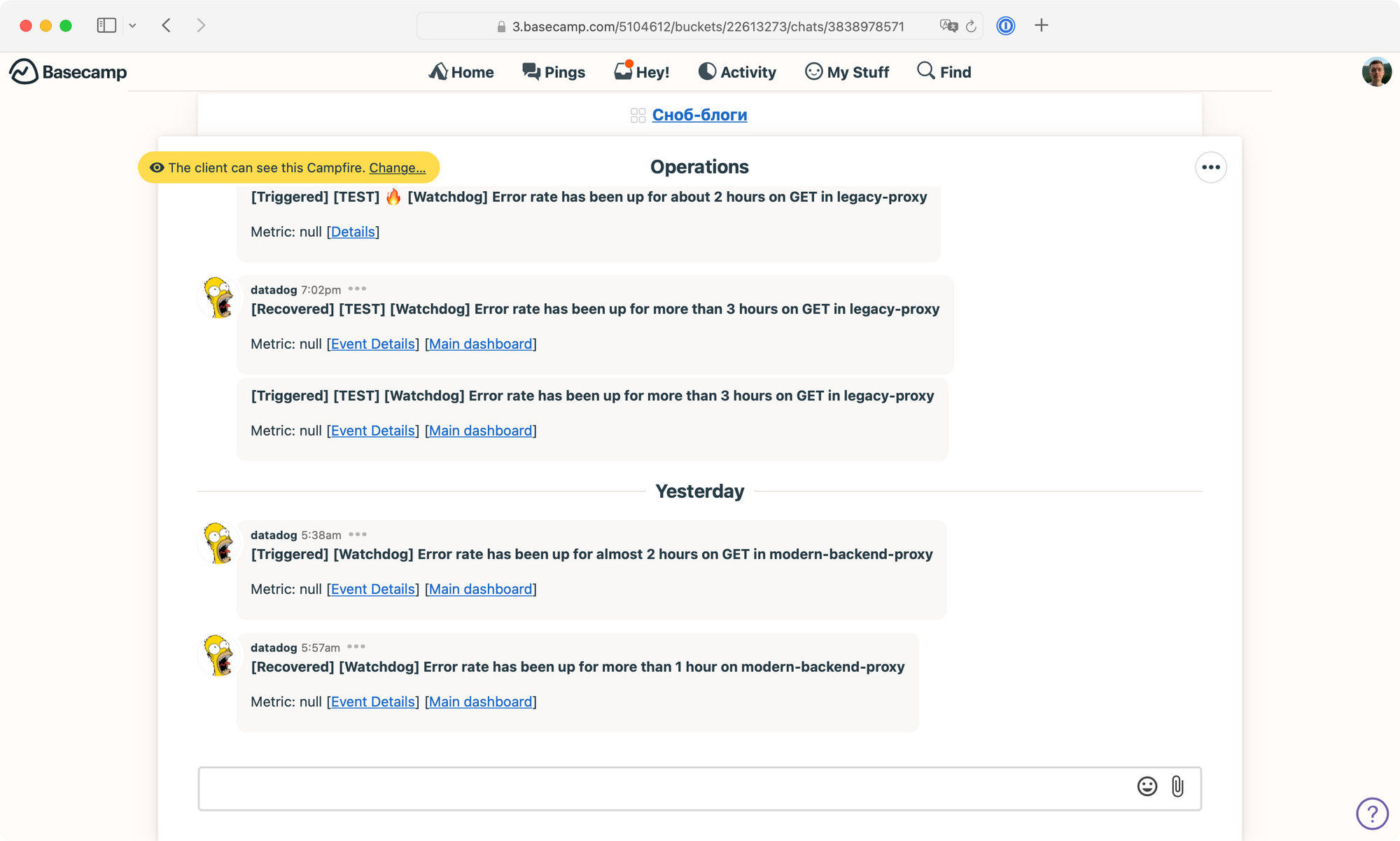
Закрытая инфраструктура создала нам ещё одну проблему — мы не могли собрать тестовые стенды. В старом коде в неподдающемся учёту количестве мест были захардкожены адреса и пароли продакшена — то есть даже если развернуть систему на машине разработчика, никто не может быть уверен, что локальный экземпляр не запишет что-нибудь в боевую базу.
Получается, что как ни пиши автотесты в нашем коде, мы не можем быть уверены в качестве системы в целом — не существует никакого способа проверить, что когда мы выкатимся на продакшен, ничего не упадёт.
Единственный подход к тестированию, который применим в данном случае — канареечный: когда мы выкатываем всю систему в прод, но показываем её минимальному количеству пользователей. Примерно за три месяца до запуска у нас в продакшене появилась рабочая система — через новый интерфейс можно было написать пост, который появился бы во сразу всех базах. При желании можно было даже вывести этот пост на главную страницу snob.ru! Конечно, система была непроработанной — сначала можно было написать только заголовок и текст, указать автора: ни о каком сложном форматировании речи не шло.
Новая система была в продакшене за два месяца до дедлайна — это дало нам достаточно времени, чтобы решить все возможные интеграционные проблемы.
Несмотря на то, что к дедлайну система была уже в продакшене, оставались самые опасные вещи — переписать DNS и включить боевой стриминг данных реальных пользователей. Опасность была в том, что старая система в совершенно непредсказуемых местах ходила сама в себя (помните вебхуки?). В коде были конструкции вида urlopen('<http://snob.ru/secret_api/secret_endpoint>');! Большая часть этих адресов оставалась работоспособной — почти весь трафик мы перенаправляли в легаси, обрабатывая самостоятельно только нужную нам часть. Но какие-то легаси-адреса всё равно сломалась — к примеру перестал работать старый механизм загрузки фотографий.
Поскольку, не переписывая DNS, мы не могли этого проверить — оставалось тестировать всё на боевой системе. Для этого мы собрали процесс, который позволяет быстро переключить трафик со старого кода на новый и обратно. Чтобы включить новый прод, достаточно было поменять адрес в Cloudflare и раскатать плейбук Ansible с обновлёнными настройками — весь процесс занимал около трёх минут. Чтобы ничего не забыть, сделали простой чеклист в бейскемпе:
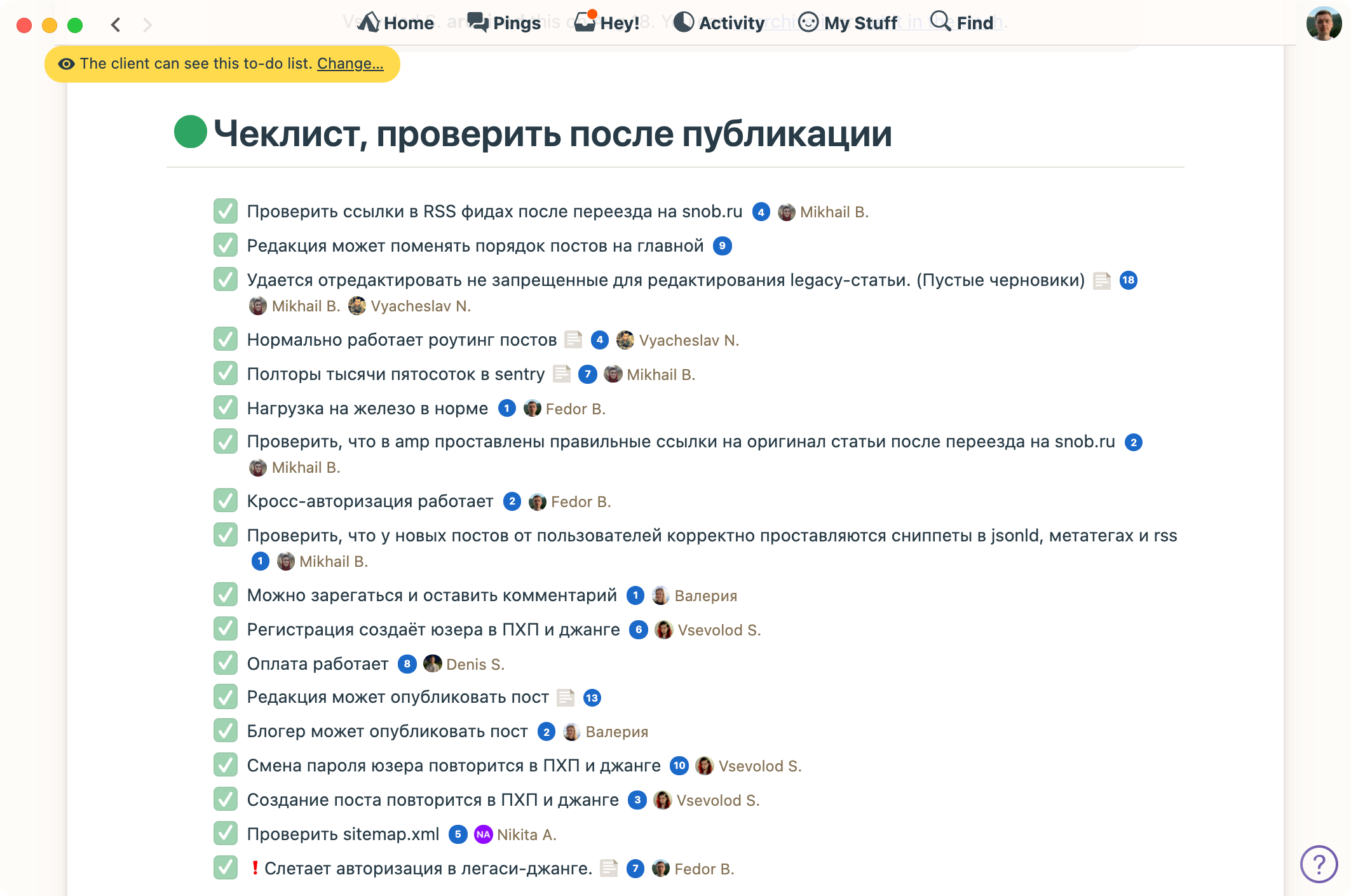
Всего мы сделали четыре тестовых запуска, все были в будни и без потери трафика. Не буду останавливаться подробно на всех проблемах, которые мы выловили в ходе тестирования — большая часть решалась тем, чтобы поправить очередную захардкоженную строку в легаси.
Сейчас у нас есть движок, в котором решены все проблемы интеграции, а код и основные пользовательские сценарии покрыты тестами. Остаётся потихоньку забирать функциональность у легаси-кода и тушить старые части системы, переводя весь snob.ru на новые рельсы. До встречи через полгода :-)
Никита Алёшников, бэкенд-разработчик
Фёдор Борщёв, технический директор
Михаил Бурмистров, ведущий фронтенд-разработчик
Самат Галимов, технический директор
Вячеслав Набатчиков, бэкенд-разработчик
Всеволод Скрипник, бэкенд-разработчик, руководитель проекта
Денис Сурков, бэкенд-разработчик
Владимир Тарановский, фронтенд-разработчик
Наш дорогой заказчик:
Марина Геворкян, генеральный директор
Валерия Тищенко, бренд-директор, продакт
Артём Алексеев, дизайнер
Мария Семенюк, директор по маркетингу
Виктория Владимирова, директор по дистрибуции
Борис Тавакалов, ведущий разработчик и хранитель знаний legacy-системы
Михаил Лавкин, системный администратор legacy-системы
Данияр Шекебаев, аналитик
Александр Тарасов, техподдержка