Улучшаем Developer Experience при помощи консольных инструментов
Чё-т я как-то пропустил, а мой доклад о том, чем удобные консольные инструменты отличаются от неудобных, опубликовали аж в двух местах. Исправляюсь!
Фёдор Борщёв
Чё-т я как-то пропустил, а мой доклад о том, чем удобные консольные инструменты отличаются от неудобных, опубликовали аж в двух местах. Исправляюсь!
Всё чаще встречаю джунов, которые плотно сидят на GPT-ассистентах, типа Copilot или Codeium. Кажется у каждой крупной корпорации, связанной с программированием появляется свой робот-помощник. Спрашиваешь такого робота «как добавить JS в Джанго-алминку?» и получаешь готовый код, который скорее всего даже заработает. Сразу чувствуешь, что будущее наступило.
Только вот будущее это — не для тех, кто бездумно пользуется такими ассистентами. Довольно мало ценности в том, чтобы переводить просьбы бизнеса в вопросы роботу — в какой-то момент такой посредник станет просто не нужен.

Профессионального роста от такого программирования тоже немного. Самое главное, что должен делать джун — это учиться: разбираться, как устроены библиотеки и как мыслят их авторы, учить языки, учиться учиться в конце концов. В общем, планомерно нарабатывать свои 10 000 часов за счёт работодателя.
Час, потраченный на изучение документации — это час, вложенный в ваш профессионализм. Час, потраченный на попытки починить GPT-код — это просто час, который вы продали работодателю, не получив ничего, кроме денег.
Доверяйте машине только те активности, которые не прокачивают лично вас — нагенерить тестов, крудов или семпловых данных. А для всего остального — читайте старую добрую документацию и скорее становитесь мидлами.
Мы с клиентом запустили стартап. Он помогает малым локальным бизнесам — кофейням, барбершопам и другим — зарабатывать по модели, которую применяют Amazon и Яндекс.
Сделали мы это с помощью технологии PWA — создали практически полноценное мобильное приложение: с офлайном, пуш-уведомлениями и иконкой на рабочем столе. В этой статье делимся, как у нас получилось успеть всё это за 6 месяцев при том, что требования постоянно менялись (стартап же!)
Большие цифровые бизнесы зарабатывают кучу денег на пакетах и подписках. Пакеты повышают средний чек, а подписки помогают получать регулярную прибыль и планировать бюджет. Amazon и Яндекс продают пакет-подписку сразу и на кино, и на доставку товаров. Apple давно сместил фокус с продажи отдельных песен на подписку на Apple Music. Пользователь тоже выигрывает — если вы постоянно пользуетесь сервисами Амазона, месячная подписка отбивается за неделю.
Если вы — владелец кофейни, и хотите продать постоянным клиентам подписку на капучино по утрам, есть нюанс: у Амазона и Яндекса есть миллионы долларов на программистов, а у вас, скорее всего, нет.
Тут на помощь приходит Dozo — проект, в котором собственную подписку или пакет может создать любой малый бизнес — от кофейни до барбершопа.
Вот они, подписки:
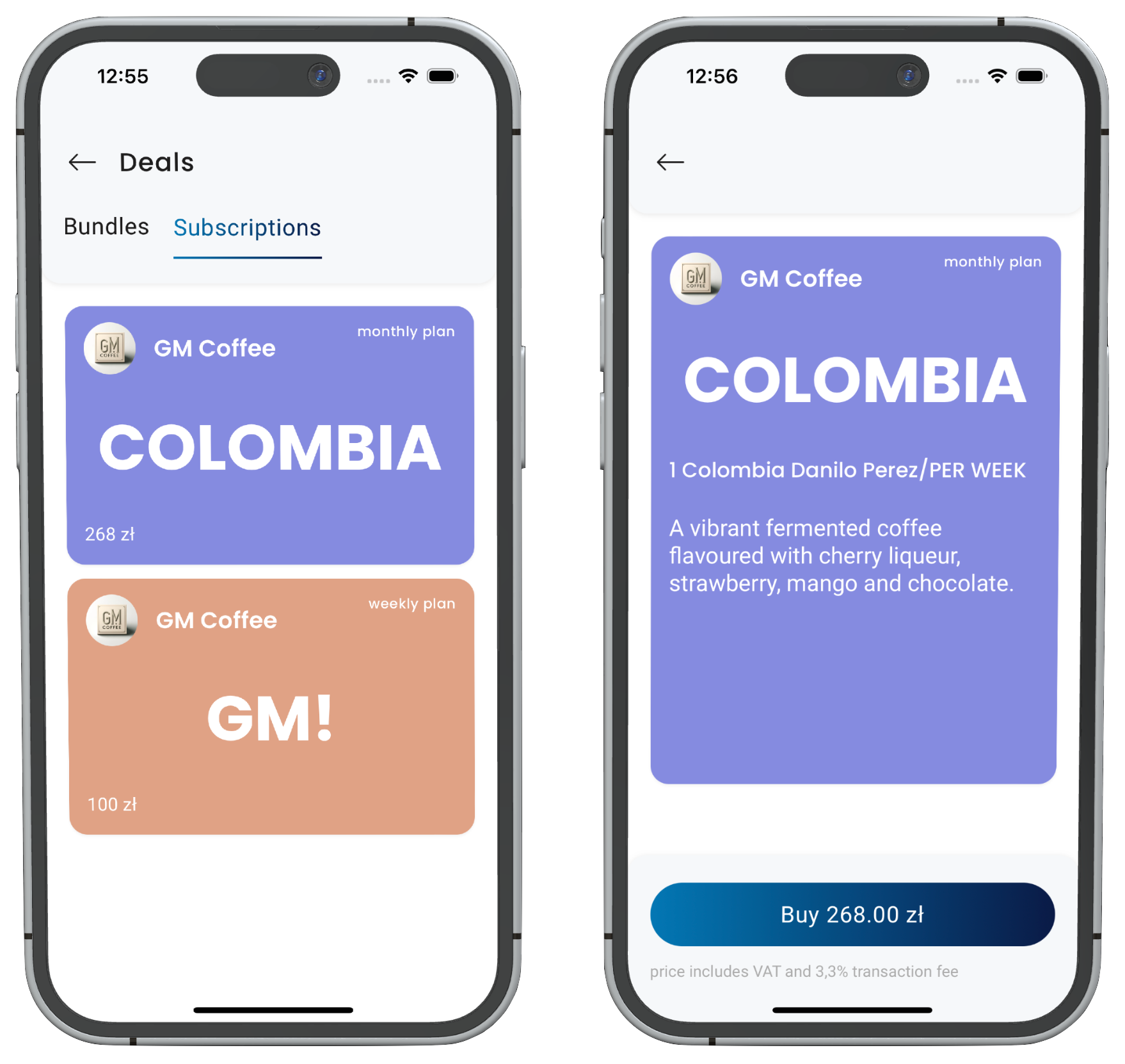
На первый взгляд, это довольно простой проект — каждый зарегистрированный бизнес создаёт свои подписки и пакеты услуг, а клиенты открывают их по QR-коду и покупают прямо в приложении.
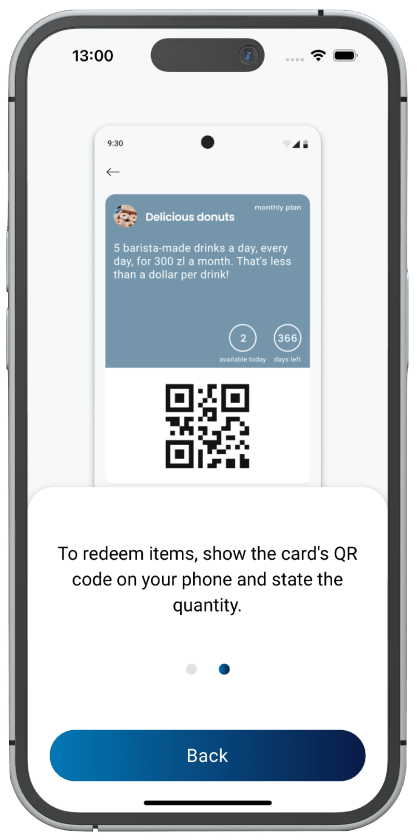
На самом деле, в нём довольно много нюансов — барбершопу и кафе нужны разные форматы меню; у одного владельца может быть несколько бизнесов, а у одного бизнеса — несколько локаций; каждому сотруднику нужна учетная запись с возможностью считывать QR-коды клиентов, но без возможности менять настройки бизнеса; владельцу бизнеса важно видеть статистику; нужна интеграция с Google Maps, платежным провайдером и SMS API; нужно правильно учитывать налоги при приёме платежей.
Любой программист знает, как больно работать с меняющимися требованиями. В этом проекте этого было очень много. Мы вместе с клиентом составили список User Stories и обновляли его после каждой встречи. Это давало уверенность, что при пересмотре планов мы не забудем ничего важного:

На старте планировали две страны и чат между пользователем и бизнесом. Через месяц стало понятно, что для тестирования гипотез хватит и одной Польши, а чат можно вообще отложить. При этом есть другие супер-важные фичи — генерация листовок с QR-кодами, или меню, где можно узнать список услуг: без них проект не запустится. А ещё отдельная история — это уведомления. Из-за того, что Apple грозились сломать пуши, а потом передумала, задачу то переизобретали, то убирали из планов, то возвращали в работу.
Для стартапа, который только пытается нащупать своё уникальное товарное предложение, найти своё место на рынке, такие резкие перемены — нормальное положение дел.
Перед тем, как написать первую строчку кода, ведущий бэкендер проекта Лёша продумал архитектуру: провёл с клиентом сессию Event Storming и построил модель данных по контекстам. Это помогло разделить стабильные и часто меняющиеся части системы — быть гибкими, но стойкими.
На бэкенде использовали Python и Django, на фронтенде Vue.js — проверенный стек, с которым у нас большой опыт и экспертиза. Для инфраструктуры использовали проверенные решения: GitHub Actions, Cloudflare и Heroku, для SMS-рассылок подключили Twilio. Для мониторинга взяли Hosted Graphite — стоит дешево, настраивается быстро. Задачи менеджили в привычном нам Бейскемпе.
Прием платежей сделали с помощью Stripe Connect — готового решения для маркетплейсов. Деньги приходят владельцам локальных бизнесов, а Dozo автоматически получает комиссию. Идеально!
В Dozo два языка: польский и английский. На старте работы макеты были только а английском. Чтобы упростить жизнь клиенту, файл с текстами переводили на польский с помощью ChatGPT, а клиент проверял результат и исправлял ошибки. Еще схема с ChatGPT сильно помогла фронтендерам с версткой: примерная длина строк на обоих языках была понятна сразу. Если бы переводов было сильно больше — подумали бы интеграцию со специализированными API для локализации вроде DeepL, но в случае Dozo это оверкил.

Ещё одна вещь, которую мы делали в первый раз — интеграция с Apple и Google Wallet. Карточки товаров из Dozo можно хранить и показывать из родных интерфейсов iOS и Android без запуска Dozo, прямо как авиабилеты. Кстати, наши карточки в электронных кошельках динамические — то есть информация в них регулярно обновляется. Если в вашем проекте нужны wallet-ы — не оставляйте задачу на последние спринты, потребуется время, чтобы разобраться с кастомизацией карточек и обновлением данных.
Dozo это PWA (Progressive Web App) — сайт, который выглядит и работает как приложение. У него куча плюсов:
Если пользовались мобильным сайтом Сбербанка или Тинькофф Банка в 2024-ом году, скорее всего вы сталкивались с этой технологией. Примеры из международного рынка — PWA приложения AliExpress, Twitter, Starbucks и Pinterest.
Невооруженным глазом PWA не отличить от мобильного приложения из Google Play или App Store:
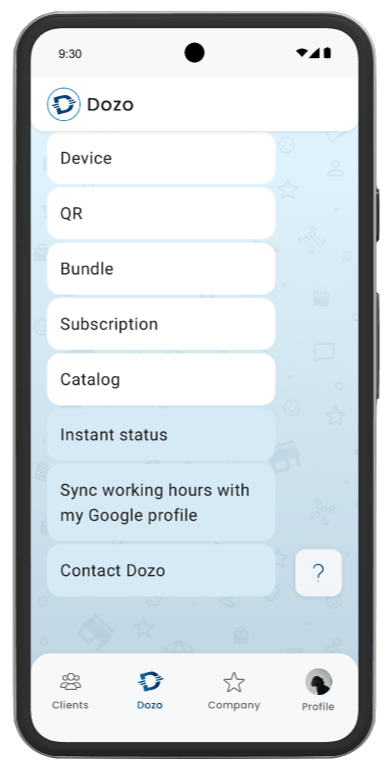
Есть и минус — на iOS нельзя выкладывать PWA в App Store, а значит пользователям гораздо тяжелоее добавить икноку на рабочий стол.
На Android (слева) можно сделать кастомную кнопку установки PWA из браузера, мы сделали баннер наверху экрана. На iOS (справа) такой возможности нет, единственный вариант— зайти в настройки сайта и нажать Add to Home Screen:
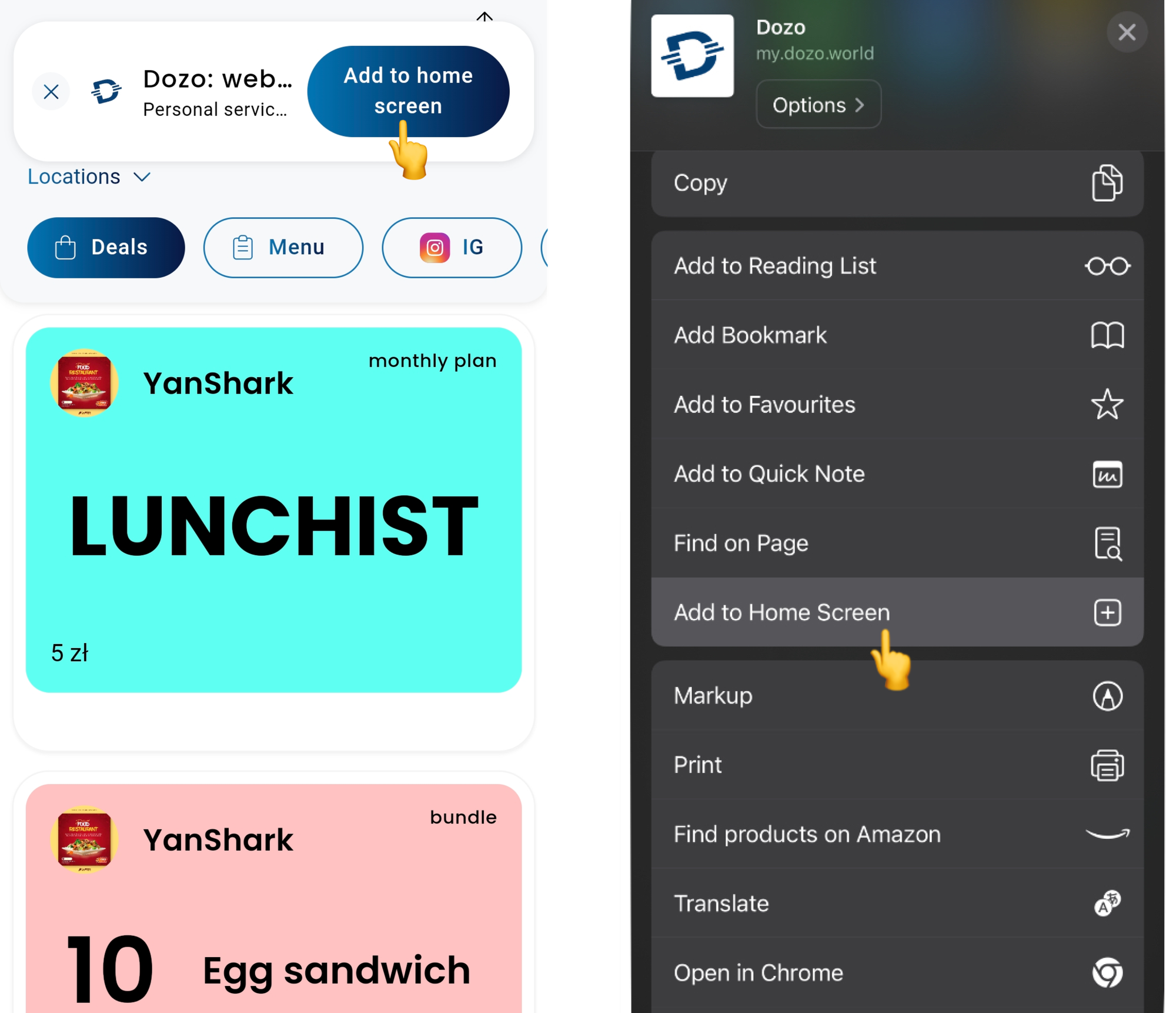
Риски PWA мы взвешивали вместе с основателем и CTO Dozo, и решили, что в нашем случае плюсы перевешивают минусы.
Итак, два месяца до запуска. Работа расписана по дням, время — ударно допиливать фичи и запускаться. В начале февраля Apple объявляет, что выключает PWA для европейских пользователей в следующем обновлении iOS.
На примере Spotify: слева как выглядит PWA на iOS 17.3.1, справа — на iOS 17.4 Beta 3. Слева, считай, приложение, справа — вкладка в браузере.
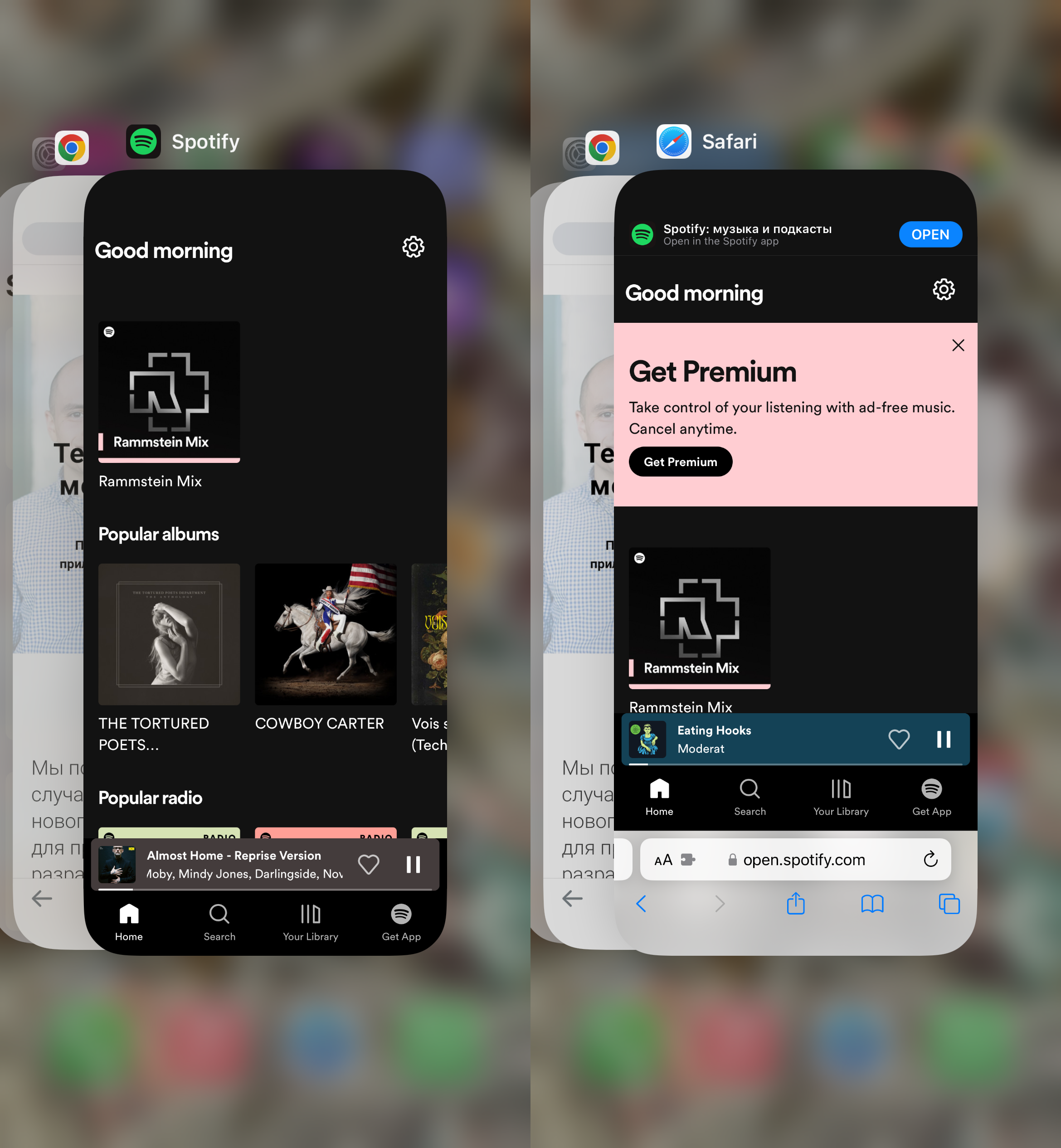
Дело в том, что незадолго до этого Евросоюз принимает закон о защите конкуренции, по которому владельцы платформ (читай Apple) не имеют права ограничивать установку сторонних программ на свои устройства. Apple нехотя подчиняется, но в ответ портит пользовательский опыт для жителей ЕС — мол, вините в этом своих политиков. Есть много мнений и аргументов о том, кто прав в этом споре.
Для нас же это выглядит как сход лавины в горном походе. Сетовать на несправедливость мира глупо, нужно искать путь в обход. Есть несколько вариантов, самый очевидный — засунуть сайт в нативную обертку, типа Capacitor-а, тогда для Apple мы будем выглядеть как самое обычное приложение. Проблема в том, что времени у нас осталось в обрез, а продакшен-опыта с Capacitor у нас не было. Решили запускаться на iOS просто как сайт.
К счастью, через несколько недель после анонса отключения PWA, Apple поменяла свое решение (кажется, сыграли роль в том числе и крики разработчиков в соцсетях) и мы запустились как планировали, со всей функциональностью, но нервы это потрепало и нам и клиенту.
От подписания договора до запуска MVP прошло шесть месяцев. Первые два месяца мы вели подготовительную работу, следующие четыре — активную разработку. Основную работу с нашей стороны сделали два бэкенд-разработчика, два фронтенд-разработчика и руководитель проекта.
Если вы живете в Варшаве — скоро сможете купить подписку на стрижки в барбершоп или комбо из капучино и булочки со скидкой в кофейне через Dozo. А наша команда продолжит поддерживать и развивать продукт после запуска.
Если хотите запустить проект с нами — пишите в телеграм или оставьте заявку на нашем сайте.
Андрей Бацунов, фронтенд-разработчик,
Алексей Богословский, ведущий бэкенд-разработчик,
Артур Даценко-Боос, фронтенд-разработчик,
Полина Никитина, бэкенд-разработчица,
Иван Седов, фронтенд-разработчик,
Инна Сидорова, руководитель проекта.
Клиники «Чайка» — это сеть премиальных клиник с отличными врачами, куда можно обратиться с любым вопросом — от сломанной ноги до зубной боли. Для организации работы, они используют собственную МИС (медицинскую информационную систему), которую пилит небольшая команда разработчиков в штате.
Нас позвали ускорить разработку этой системы. Это классическая история, когда за годы развития продукта, техническая команда оказывается погребена под сложностью проекта и то, что раньше занимало дни, теперь занимает месяцы. Ещё опаснее то, что разработка перестает быть предсказуемой — бизнес перестает верить обещаниям разработчиков.
За год работы мы придумали и частично внедрили новую архитектуру, принесли новый язык программирования и кучу технических решений, с помощью которых смогли запустить несколько полезных сервисов.
В этом посте мы расскажем не только об успехах, но и о проблемах — какие ошибочные решения мы приняли по интеграции, как создали дополнительный техдолг, и, кажется, не успели сделать главное.
Сначала нас позвали как консультантов: команда разработки медленно пилила фичи, нанять новых людей было трудно, а те программисты, которых всё-таки нанимали — увеличивали фонд оплаты труда, но не ускоряли существенно разработку нужных бизнесу фичей. Бизнес хотел понять, в чем причина и как эту ситуацию изменить.
До этого проекта, у нас был опыт «технологической трансформации» команд разработки и тогда мы зареклись делать «консалтинг» — это работа, в которой нужно 100% вовлечение технического директора и её сложно делегировать — такой бизнес мы с Федей масштабировать не умеем, а повторять одно и то же, чтобы просто заработать денег — скучно.
Тогда мы придумали, что гораздо быстрее и эффективнее будет менять техническую архитектуру и производственные процессы компаний, если мы придем с небольшой собственной командой разработки и своими руками внедрим новую архитектуру — не расскажем, а на примерах покажем, как работать эффективнее. Проложим рельсы, по которым будет удобно ехать и команде разработке и бизнесу. Именно с этой идеей мы и пришли в Чайку.
Существующая МИС решала кучу задач, автоматизируя работу клиник со всех сторон — от ведения медицинских карточек до учёта денег, заплаченных пациентом. Варианта переписать какую-то её часть, временно остановив разработку, как мы сделали в Вебиуме или Снобе, у нас не было — бизнес растёт, и открытие новой клиники в Тбилиси не будет ждать, пока мы перепишем миллион строк с TypeScript на Python.
Всё это осложнялось тем, что медицина — самая сложная доменная область, с которой мы встречались. Каждая, даже самая простая задача в ней, на проверку оказывается верхушкой гигантского айсберга. Взять хранение диагнозов. Казалось бы — одна таблица для пациентов, вторая для диагнозов, выбранных из стандартного справочника, третья для их связи. Но нет. Первичный ли это диагноз? Он уже подтверждён, или это промежуточный результат диффиренцированного диагноза? Его поставил один доктор или коллегия? А может это результат автоматизированного измерения? Актуален ли диагноз сейчас, или это запись из анамнеза? По какому справочнику этот диагноз — МКБ или SNOMED? А если диагноз «перелом», то он где — на руке или ноге? Правой или левой? А куда записать информацию об аллергии?
К счастью, в проекте была сильная продуктовая команда: продакты с медицинским образованием и дизайнер с большим опытом работы над проектом — они были нашими основными партнерами в этой работе.
Текущую разработку замораживать нельзя, так что новый код для бизнес-фич надо писать сбоку. Учитывая, что бекенд написан на чужом для нас стеке (TypeScript), единственное решение — это event-driven архитектура. Пусть текущая МИС будет одной из многих систем в гетерогенной среде, где программы, обслуживающие разные части бизнеса, общаются друг с другом через события. Скажем, сотрудник ресепшн завёл карточку пациента в привычном интерфейсе — система сформировала событие «пациент заведён», обогатила его всеми данными пациента, и положила это в общее информационное пространство — брокер событий. Все другие программы, которым нужна информация о пациентах, слушают, поток событий и заводят пациента у себя. Точно так же передаются данные о новых докторах, диагнозах, операциях, взаиморасчётах и всех других изменениях в системе.
Чтобы не изобретать велосипед, мы построили свою модель данных на основе готового стандарта — FHIR. Кроме прямой пользы — держать данные в едином стандарте, FHIR помогал нам погружаться в доменную область — изучая описание стандарта, легко узнать, что диагнозы надо привязывать к частям тела (диагноз «кариес», часть тела «22 зуб со стороны языка»).
Создав модель событий, мы сможем легко перезапускать систему частями — скажем, если бизнес планирует открывать новые клиники в Дубае, мы можем фокусироваться на интеграции с местными кассовыми аппаратами, без которых бизнес не запустишь, не переписывая при этом медицинскую часть.
Одно дело — красивая архитектура, а другое — реальная жизнь. Найдём ли мы все нужные точки в монолите, которые меняют данные в базе, чтобы генерировать в них события? Сможем ли мы гарантировать 100% доставку этих событий? Найдутся ли у команды монолита силы, чтобы выполнить все наши требования? Сможем ли мы жить в инфраструктуре, которую поддерживают сторонние сисадмины?
Начинать большой проект, не проверив эти риски — глупо: можно влить кучу человекомесяцев, а в конце узнать, что проект никогда не запустится, потому что события 2% случаев просто теряются, и данные о новых пользователях не долетают до всех систем. Мы начали с маленького — решили сделать сервис, который проверял бы все риски интеграции, но не стоил как космолёт. Выбрали AstraShare. Его идея простая — когда врачи Чайки направляют данные пациента в стороннюю больницу или в страховую компанию, можно не печатать сотни страниц истории болезни, а сделать сервис, в котором эти данные можно будет получить в электронном виде, или скачать PDF и распечатать самому. А у нас останется инструмент коммуникации со всеми, кто пользовался этим сервисом и уверенность, что данные получены кем надо.
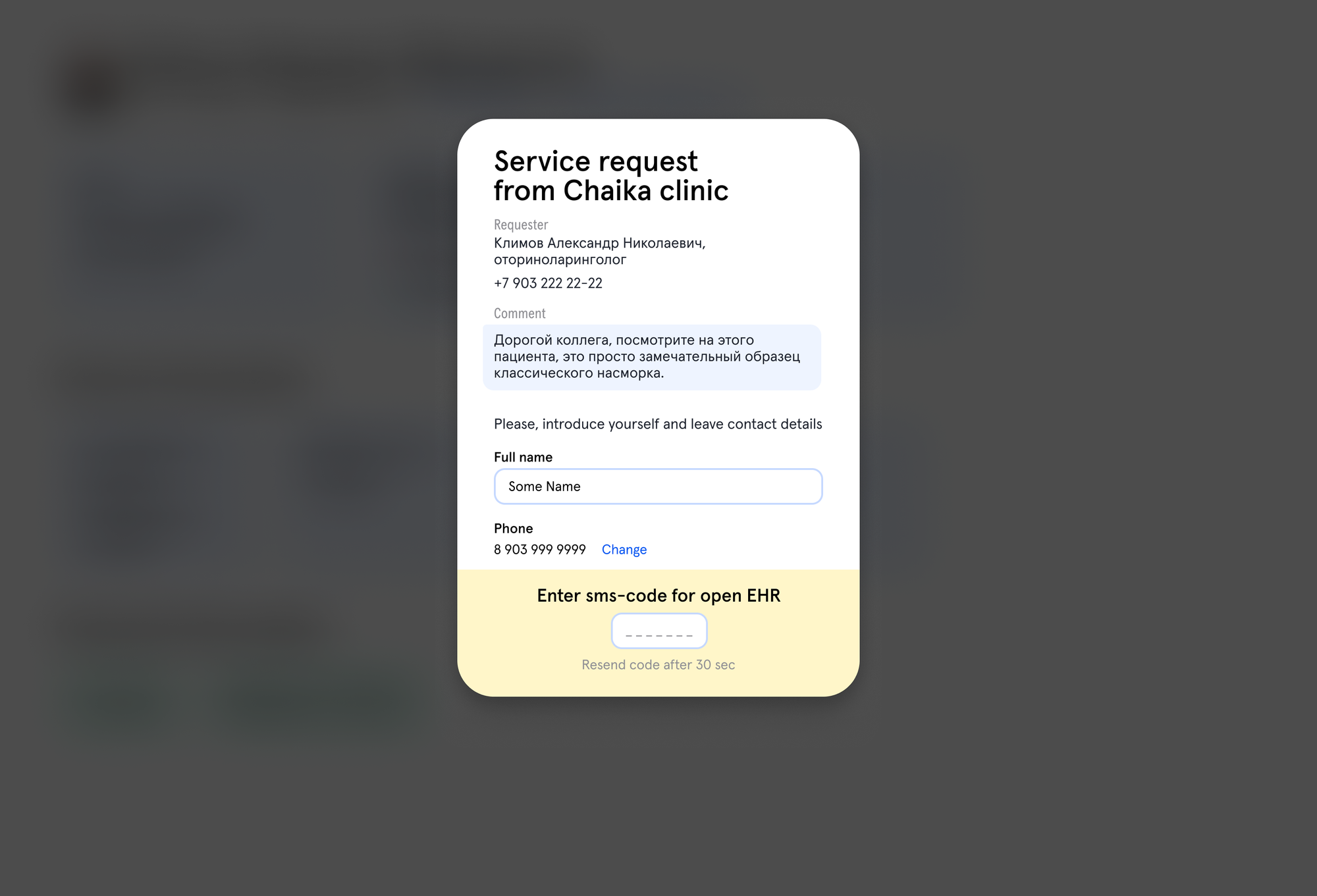
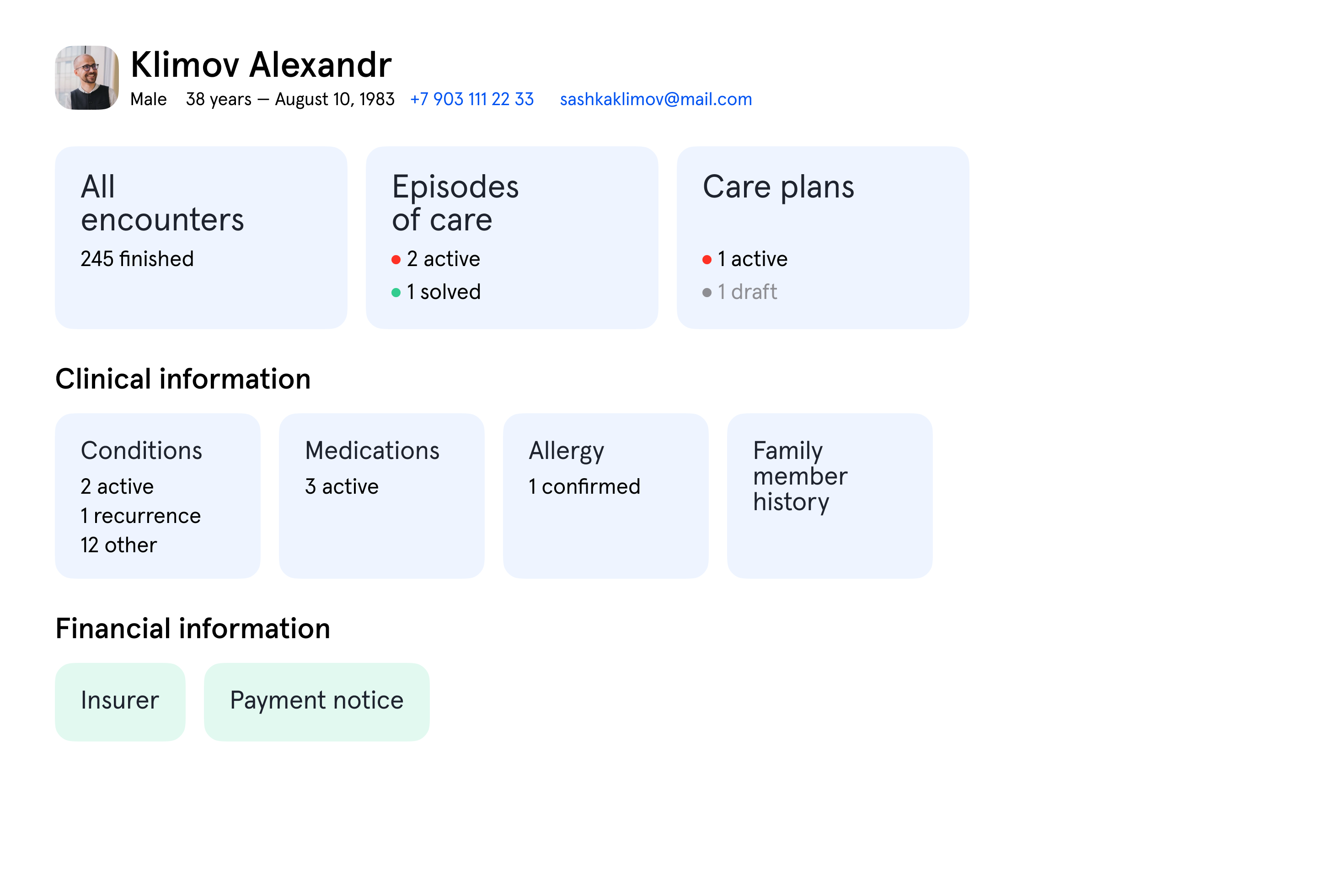

Сервис мы в итоге запустили за 5 месяцев силами команды из трёх программистов и одного архитектора. Чтобы упростить задачу команде клиента, мы пожертвовали проработкой событийной модели: вместо десятка «удобных» событий «заведён пользователь», «поставлен диагноз», «сделано наблюдение» сделали одно большое событие «медицинская запись изменена», данные из которого уже разбирали в нашей системе. Но даже такое гигантское событие доставлялось плохо — примерно в 0.5% случаев событие не генерировалось. Чтобы понять, насколько это много, представьте, что из вашей карточки в стоматологии с такой вероятностью пропадёт информация о вашей аллергии на обезболивающее.
Для решения этой проблемы, мы дали возможность администраторам переотправлять карточки в сервис. Как бы грустно для программистов это ни звучало, для бизнеса результат был отличный — они получили новый сервис и команду, которая точно знает, что может сделать, а что — нет. Чёткое «нет» от программистов — вообще очень важная штука: гораздо лучше, чем «да», которое превращается в «нет» через полгода, когда клиентам или партнерам уже обещан новый сервис.
Итак, мы убедились, что архитектура работает. Время браться за более сложные задачи! У бизнеса было три основных запроса: улучшение системы биллинга, мета-лаборатория и новый интерфейс стоматологов. Рассказ о биллинге здесь опустим — это довольно скучная (хотя и безумно сложная для новичков) штука, которую мы успешно делали уже много раз. А вот о лабораториях и интерфейсе стоматологов расскажем подробнее.
Чайка работает с несколькими лабораториями, отсылая туда пациентов и забирая результаты анализа. Конечно, эту работу нужно максимально автоматизировать — чтобы клиентам не приходилось таскать справки из лабораторий, а медсёстрам — забивать в систему данные из них, попутно допуская ошибки. В идеале мы выписываем направления на анализы в своей информационной системе и через какое-то время в карточке пациента автоматом появляются результаты анализов, а врач с пациентом получают об этом уведомление.
Любая интеграция такого рода — это сложная задача: другие системы делали программисты со своим представлением о доменной области, о структурах данных и о том, что такое надёжность передачи информации. Одна лаборатория поддерживает FHIR, но с каким-то другим справочником, другая — отдаёт результаты в виде XML-файлов, которые забирает с сервера специальная софтина на винде, у третьей — свой собственный REST API с особым способом аутентификации.
К тому же сразу после запуска сложных интеграций нужно закладывать период в 1–2 недели, когда всё работает нестабильно, а программисты почти в реальном времени правят мелкие несоответствия в форматах данных или протоколах. Это довольно сложно делать на старом монолите из-за длинного релизного цикла: внести одно изменение на проде почти нереально, нужно подсаживать его в «релизный поезд» — пачку изменений, которая уходит на ручное тестирование и будет выпущена только после того, как все фичи из неё будут проверены. В таком режиме даже маленькие исправления могут ждать света дня неделю.
В новой архитектуре у нас получилось реализовать этот модуль отдельным сервисом силами 4 программистов за 6 месяцев.
После того, как мы убедились, что мы с бизнесом Чайки умеем говорить на одном языке, и при этом ещё и поставлять работу вовремя — настало время больших проектов.
Цель, которую мы ставили с самого начала сотрудничества — сделать удобный интерфейс для врачей. Информационные технологии не сильно поменяли рутину докторов: они как заполняли карточки в 80-х годах прошлого века, так заполняют и сейчас. Правда карточки теперь показываются на экране монитора, а подписи под ними стали электронными. Мы решили это исправить.
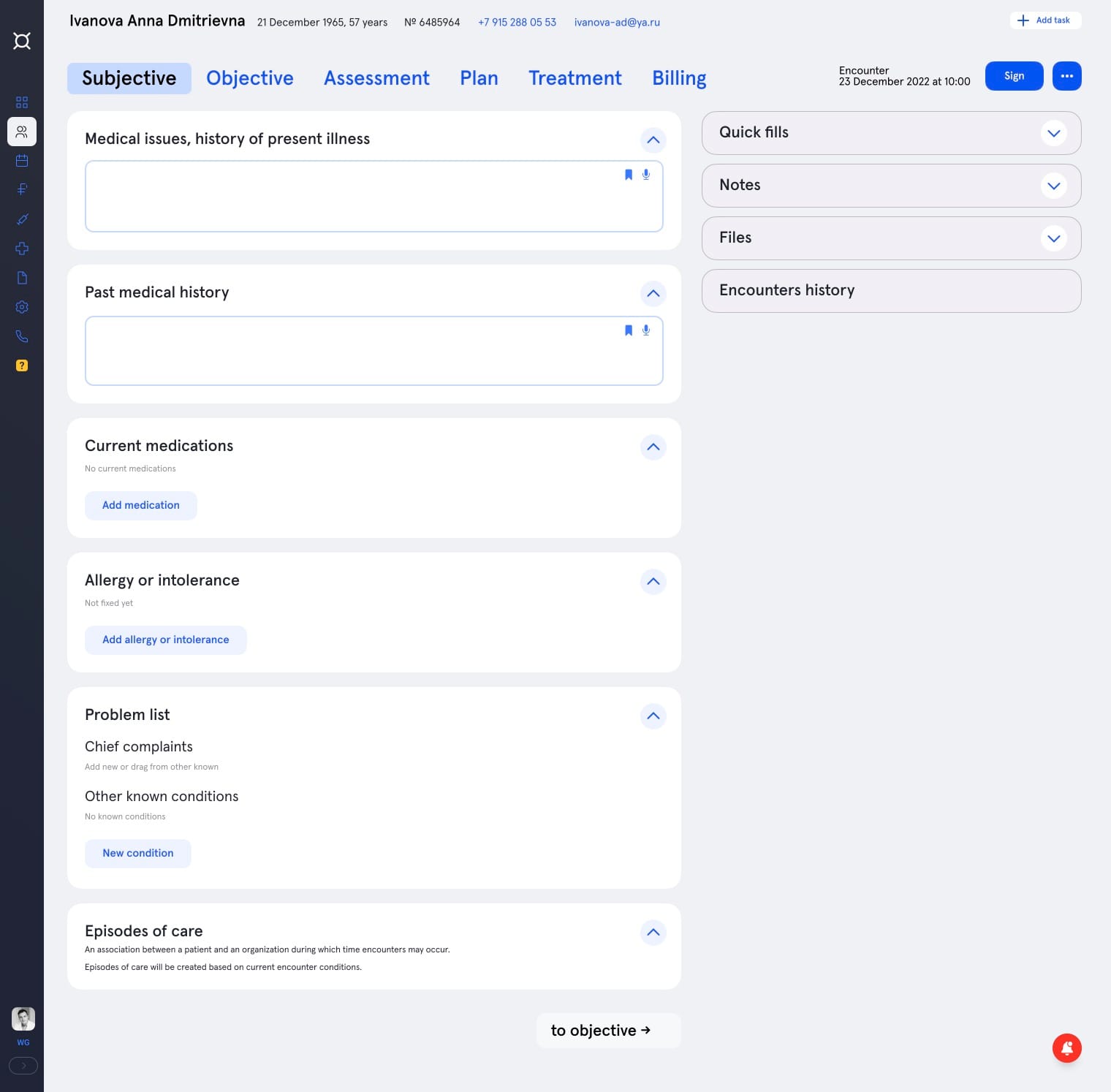
Дело в том, что врачи вынуждены заполнять карточки примерно так же, как они хранятся в базе данных: выбрать пациента, указать диагноз, записать текстом наблюдения. То есть удобно для программистов и неудобно для врачей. При этом уже в 60е годы был разработан эффективный формат клинических заметок — SOAP, в котором записи делятся на 4 блока: Subjective (Субъективный), Objective (Объективный), Assessment (Оценка) и Plan (План). Новый интерфейс использует эту же схему, ускоряя заполнение информации, где это возможно.
Внедрить такую систему «на живую» очень сложно: медицинские карточки — это сердце МИС. Чтобы не переписывать всю работающую систему без необходимости, мы выбрали небольшой, и по совместительству самый интересный кусок работы — стоматологов.
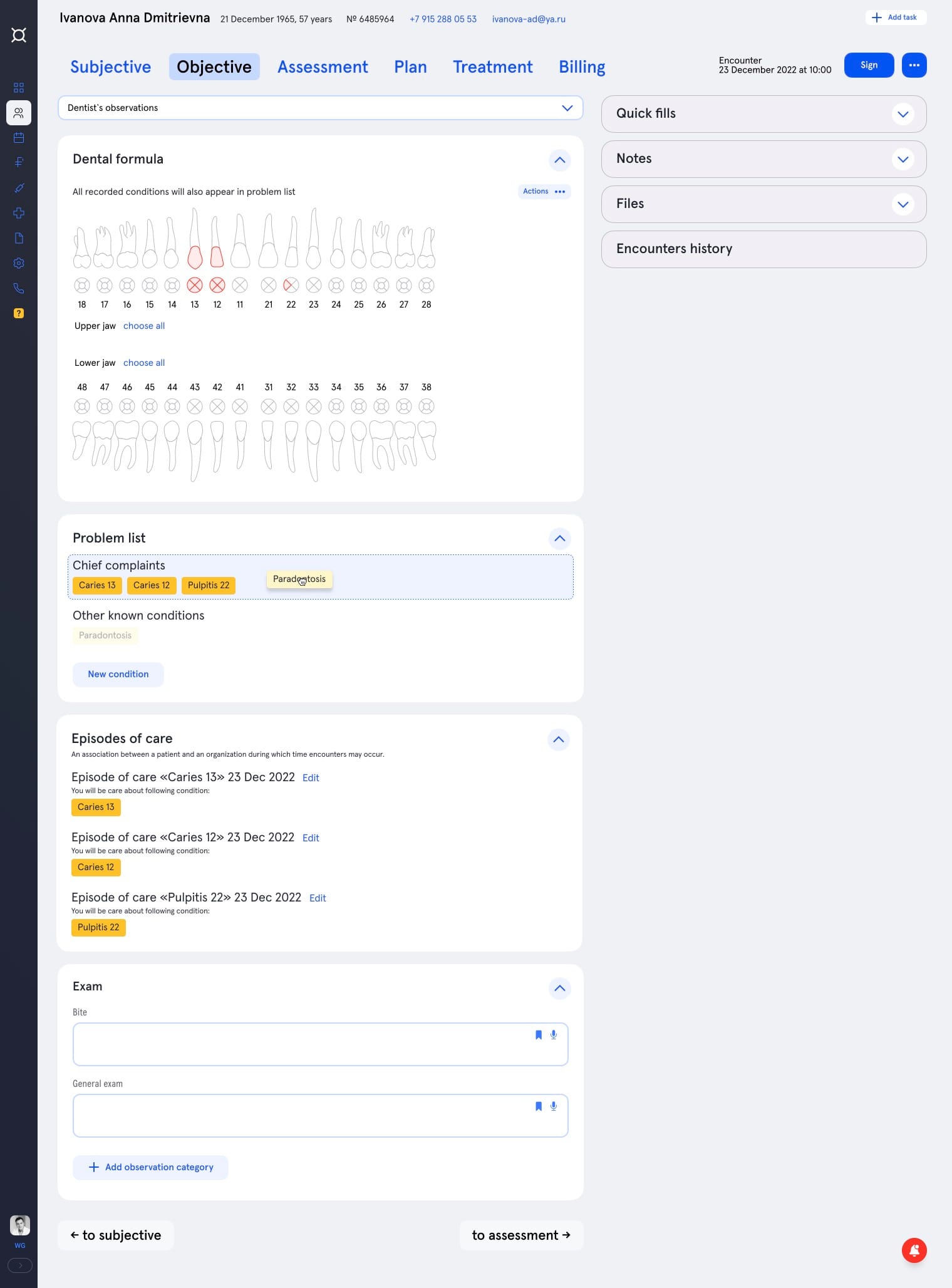
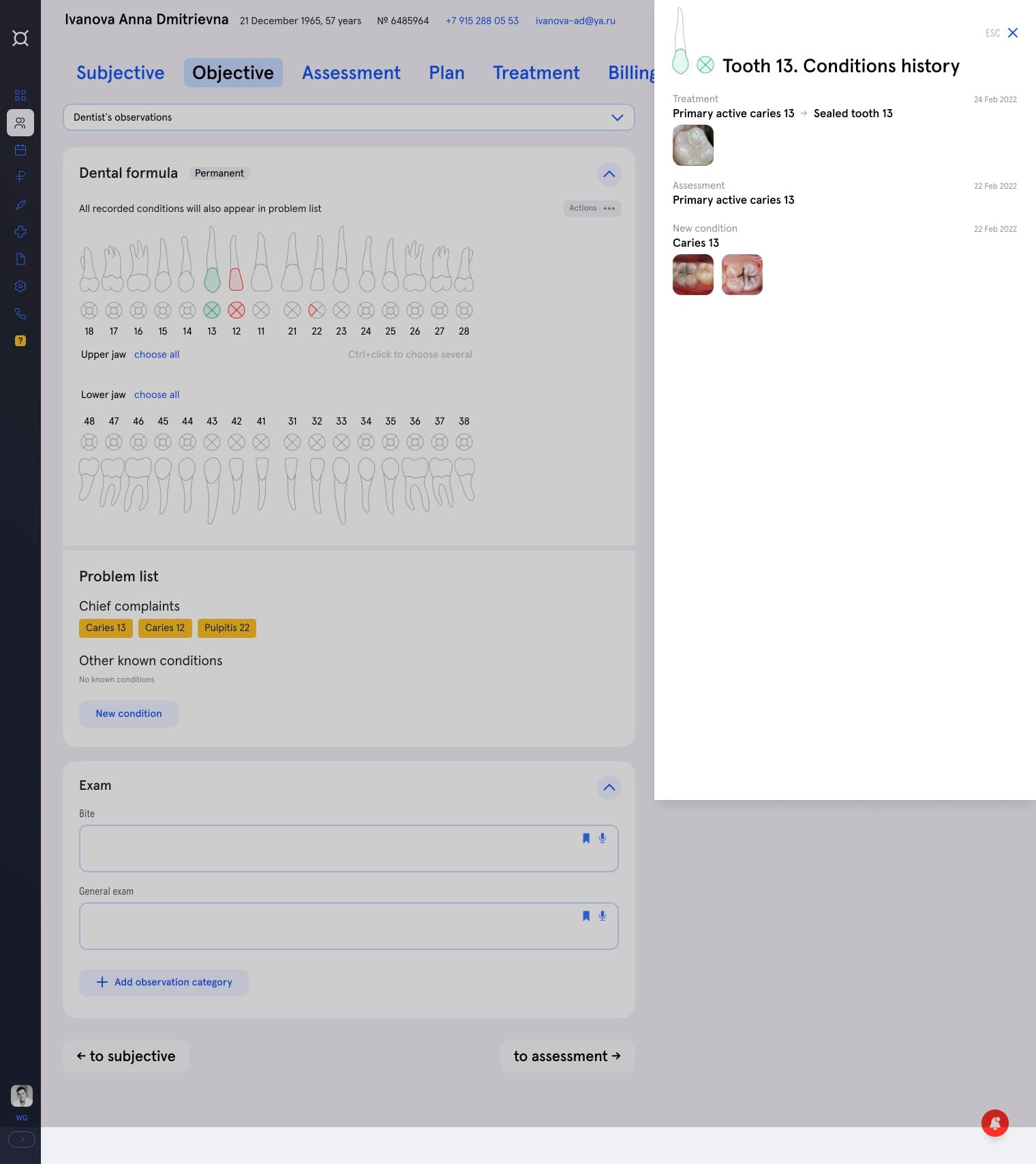
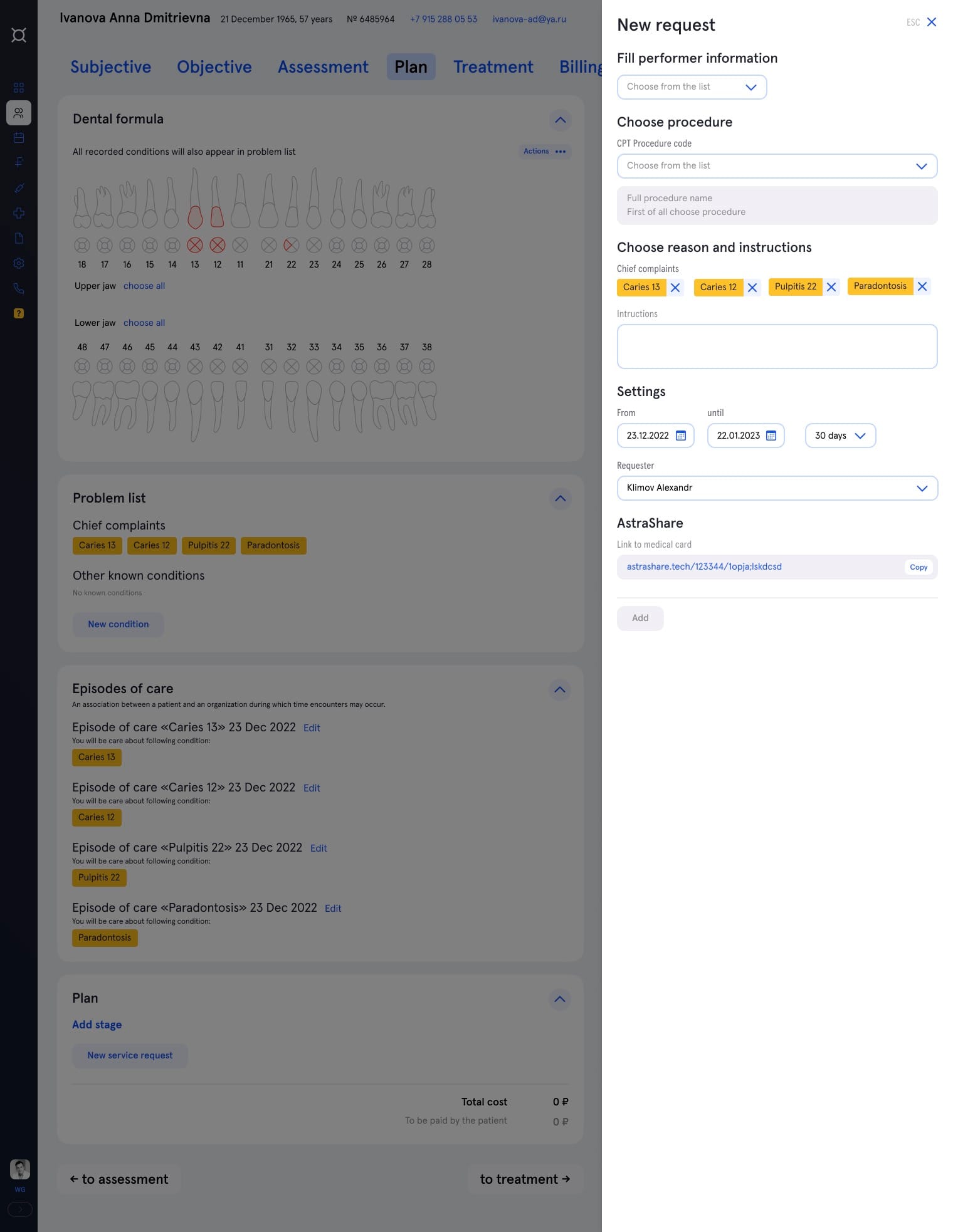
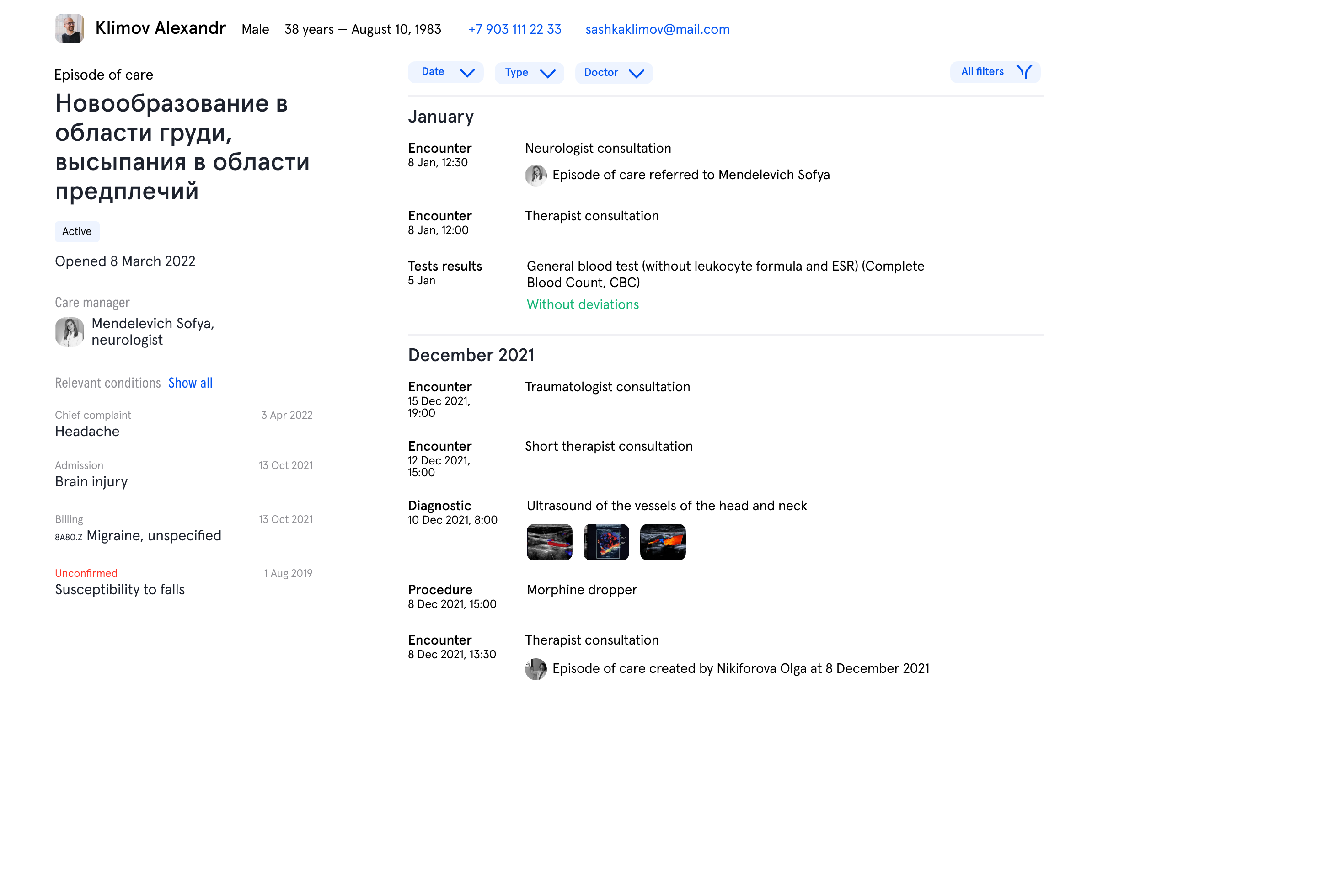
Дантисты отличаются от других докторов тем, что у них все наблюдения и все операции группируются вокруг конкретных зубов. Собираясь работать с верхним правым клыком, доктору интересно посмотреть его историю — медицинские снимки, историю пломбирования. В текущем интерфейсе для этого нужно пролистать медицинские записи от всех предыдущих посещений, в которых будут не только соседние зубы, но и визиты, например, к эндокринологу.
Дизайнеры Астры выстроили удобный интерфейс для докторов на основе зубной формулы:
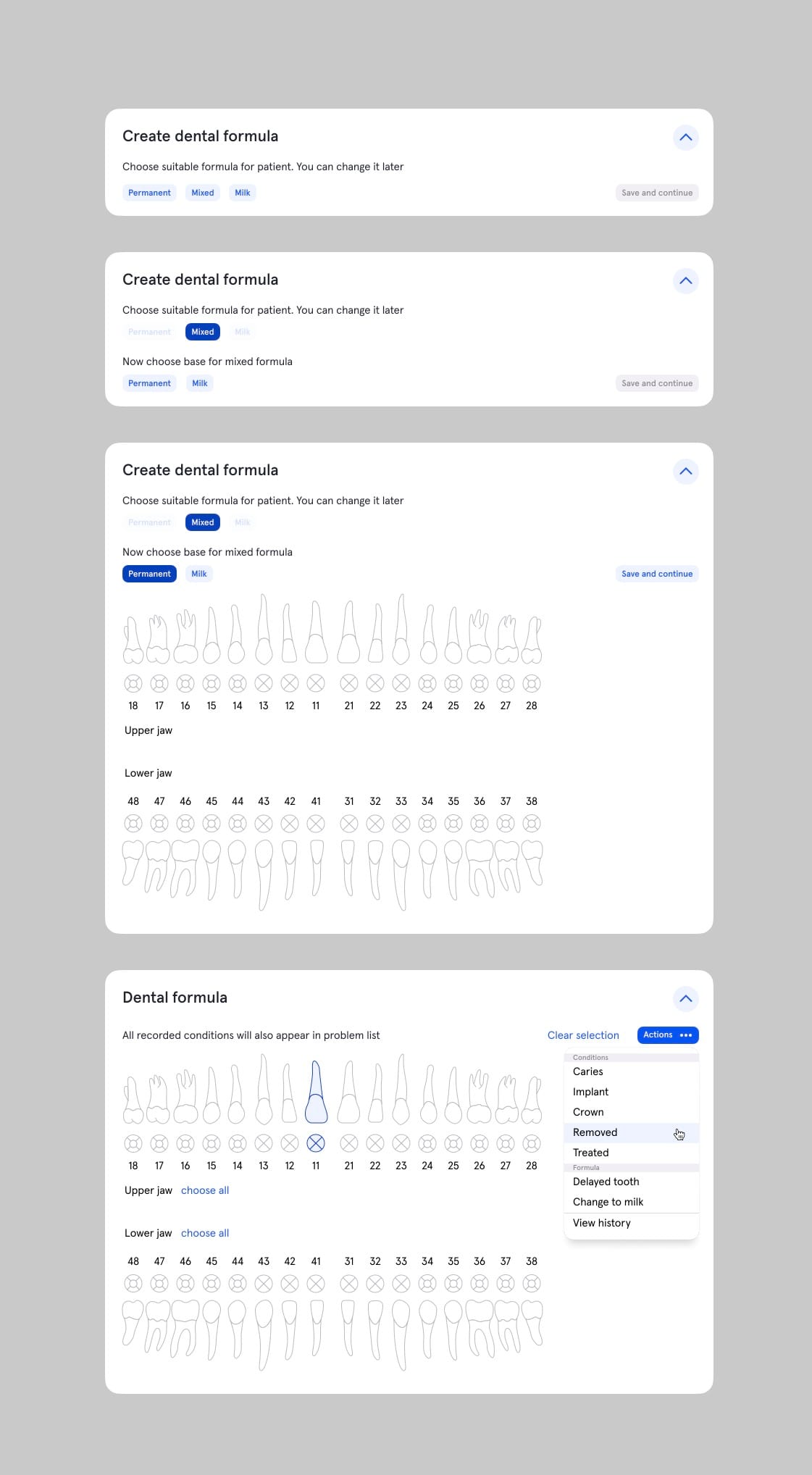
С технической точки зрения задача оказалась сложнее, чем все предыдущие — нам нужно было намного глубже интегрироваться со старой системой: добавить дополнительных данных в стриминг событий, расправиться с техдолгом в стриминге, сделать кросс-авторизацию, чтобы пользователи могли бесшовно переходить между старой и новой системой.
Для обеспечения бесшовности, мы придумали, как быстро встроить свой фронтенд в существующий. Для этого существуют несколько инженерно красивых решений вроде микрофронтендов, но в нашем случае, результат нужно было показать как можно быстрее, поэтому решили не пилить свой фронтенд сбоку, а поработать в текущем, то есть отложить в сторону любимый vue.js и поработать с react.
Такое решение, хоть и позволило нам на первых порах ускориться, стоило очень много нервов — уж очень тяжело было приносить свои стандарты разработки в текущую команду. Самой острой проблемой стали линтеры — ребята предпочитали много правил держать в голове, а мы привыкли к максимально жёстким линтерам, которые гарантируют исполнение договоренностей. Вторая проблема — это релизный цикл: старый фронт живёт с релизными поездами, с которыми мы работать не привыкли и честно говоря не готовы. Здесь приняли довольно тяжёлое решение — в старом проекте релизные поезд пусть ходят как есть, а весь наш код едет напрямую в продакшен. Получилось, что мы работаем по привычному gitflow, а штатные ребята — недельными релизами. Конечно, изменения, затрагивающие общий код, мы прогоняли через поезда, но всё равно, продакшн мы разочек положили. Не делайте так.
В итоге мы разработали отличный продукт, но не смогли запустить его в продакшен из-за внешних причин, связанных с мобилизацией. Этот сервис, да и в целом планы по дальнейшему переводу сервисов на новую архитектуру пришлось положить на полку.
В результате, мы запустили несколько классных сервисов, закрыли несколько горящих задач бизнеса. Но большая цель: «получить такую техническую часть проекта, такую команду, которая будет предсказуемо и быстро решать задачи бизнеса» — осталась нерешенной.
Для нас такое завершение сотрудничество было ударом. Представьте, что вы посвятили полгода своей профессиональной жизни на проект, который приходится закрыть. У нас нет претензий к заказчику — произошел форс-мажор.
Интересно, получилось бы довести этот процесс до конца, будь у нас чуть больше времени? Мы считаем, что да. Выбранная архитектура доказала свою состоятельность — мы перезапустили большие и сложные части продукта без остановки бизнес-процессов, дальнейший переезд на новую архитектуру был хоть и сложной, но понятной работой.
А что насчет ускорения проекта? Можно ли было успеть достичь «большой цели» быстрее? Конечно да. Можно было рискнуть и начать разработку большого сервиса не проводя полноценный тест на маленьком. Можно было ещё больше напрячь продуктовую команду и запустить больше проектов в параллели. Все эти шаги увеличили бы риски проекта выше комфортных для нас и для заказчика.
Если же сделать шаг назад и вспомнить о «генеральной гипотезе», что технологическую трансформацию бизнеса проще реализовать, приведя с собой небольшую, но супер высококвалифицированную команду разработки и внедряя изменения её руками — то тут мы считаем, что эта гипотеза в целом оправдалась. Прямо сейчас мы запускаем ещё один подобный проект. Надеюсь, что в этот раз мы сможем довести его до конца.
Если вам нужна подобная помощь или просто классная разработка — пишите Самату Галимову @samatg.
—
Технические директора:
Фёдор Борщёв
Самат Галимов
Архитектор:
Антон Давыдов
Бекенд-программисты:
Вячеслав Набатчиков
Денис Сурков
Алексей Чудин
Эдуард Степанов
Николай Кирьянов
Даниил Мальцев
Владимир Войтенко
Анна Агаренко
Фронтенд-программисты:
Александр Нестеров
Алексей Богословский
Владимир Тарановский
Тимур Брачков
Михаил Бурмистров
Менеджеры:
Анастасия Шаркова
Ксения Сафронова
Иван Борисов
Дарья Львова
Сотрудники заказчика:
Алена Салкова
Александр Скоромнюк
Александр Климов
Валентин Раншаков
Виктор Косарев
Вячеслав Ключников
Денис Турьяница
Дмитрий Верижников
Дмитрий Зозулин
Дмитрий Афанасьев
Дмитрий Панов
Мария Чистова
Павел Власенко
Ребята с PiterPy выложили двухчасовой сеанс лайвкодинга, где я 2 часа (!) вживую (!) делаю проект на Django, в котором кайфово: