Хороший менеджер задаёт этот вопрос во время каждой своей активности.
Какую ценность я добавил, когда сходил на встречу? Был ли полезен, принёс что-то новое или тупил в фейсбук?
Какую ценность я добавил, когда ответил на письмо? Легче ли стало совершить следующий шаг по проекту?
Какую ценность я добавил, когда поговорил с программистом? Стало ли ему понятнее, что и как делать на проекте?
Какую ценность я добавил за неделю руководства отделом? А за месяц?
Если нечего ответить, значит пора переставать заниматься деятельностью, которая не приносит ценности: отказаться от встреч с командой, которой ты не нужен, не слать пустые отписки на письма, не отвлекать программистов. Или просто отдохнуть.
Это — тупое правило, которое здорово помогает во всех спорных ситуациях.
Программист не сдал задачу вовремя, потому что не знал? Покажи, где это было написано. Если не нашёл — значит, дедлайна не было.
На встрече договорились что-то сделать и не записали? Значит, никому не надо.
Правило «не написано, значит, не было» здорово мотивирует писать минутки ко всем встречам и поддерживать актуальность задачников. Если тебе что-то от кого-то нужно, значит, ты сядешь и напишешь задачу с дедлайном — иначе тебя пошлют нафиг и будут правы.
Неопытные менеджеры часто строят разговоры с программистами на давлении. Начиная от банального «5 дней, говоришь? А может, давай за 4, но без тестов?» и заканчивая манипулятивными просьбами расписать подробную смету по часам на каждое требование.
Это — ошибка: даже если программист под давлением пообещает срок меньше, результат от этого не приблизится. Во-первых, программист будет помнить, что срок назвал не он сам, а менеджер, а значит, если этот срок проебать, то уже не так и стыдно. Во-вторых, количество работы всё равно не уменьшается — если сделать пятидневную задачу за три дня, то оставшиеся два (а может, и больше) попадут в техдолг и выстрелят через пару месяцев.
Ну и, конечно, такие менеджеры не ценят своё время: гораздо проще получить предсказуемый результат через 5 дней, чем непредсказуемый через 3, но с риском потратить ещё 5 на исправление последствий техдолга или отношений с заказчиком.
Единственный нормальный способ уменьшить названный программистом срок — это спросить у него совета, какое требование из задачи выкинуть, чтобы стало легче работать. Все остальные — манипуляции, которые не приведут ни к чему, кроме сорванных дедлайнов.
Вот упал у вас прод, вы заходите по ssh и видите, что Load Average в 10 раз больше, чем количество ядер. Люди не могут воспользоваться сервисом, партнёры задают вопросы, а всё, что вы знаете, — это то, что нагрузка выше номинальной. Где именно, из-за чего всё это случилось — непонятно.
Вы залезаете в консоль, ищете по логам (медленно, сервер-то перегружен), запускаете ps и strace, совершаете другие шаманские действия. Чувствуете, что двигаетесь по тёмному лесу с закрытыми глазами, как бегуны из старого клипа Pendulum.
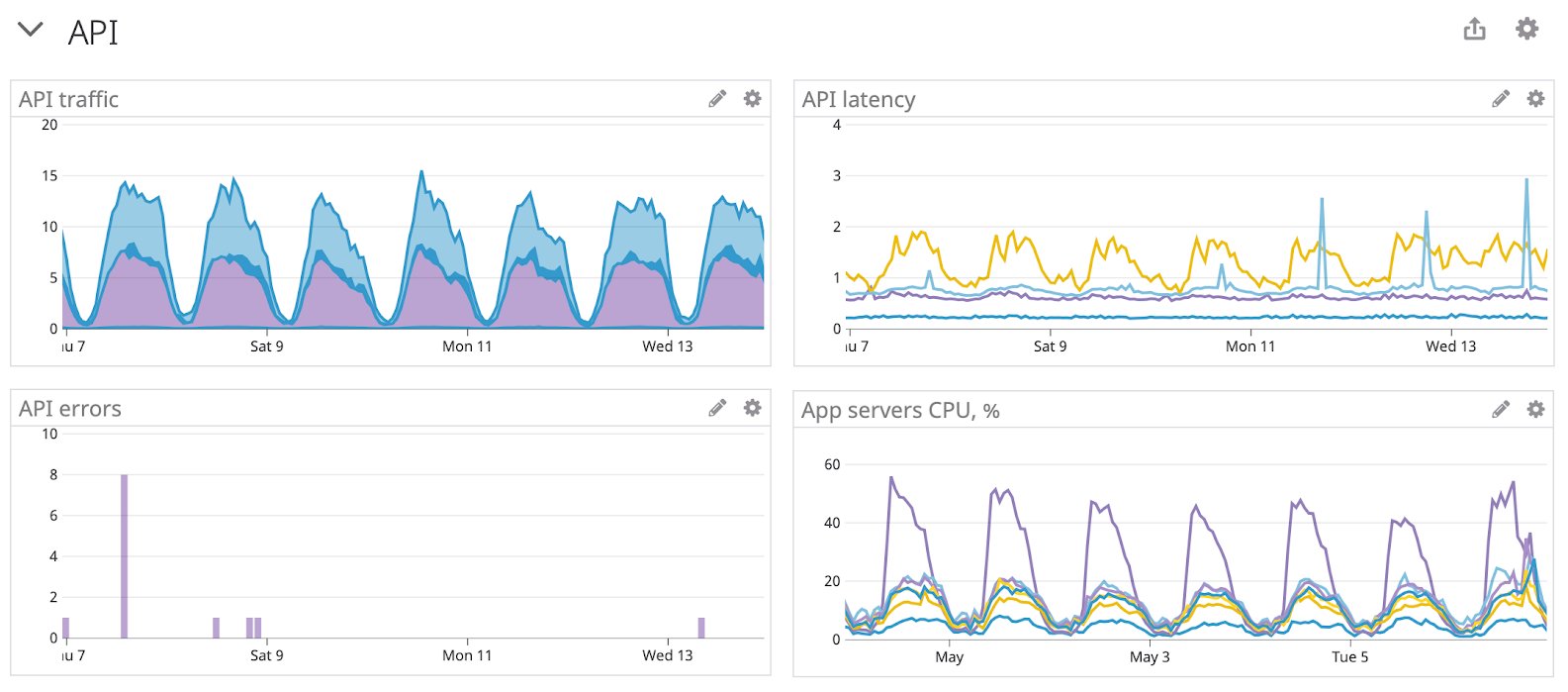
Четыре золотых сигнала — время ответа, количество запросов, рейт ошибок и запас нагрузки
Выход простой — сделайте себе нормальные органы чувств. Заведите дашборды, которые покажут 4 золотых сигнала (время ответа, количество запросов, рейт ошибок и запас нагрузки) и ТОП-10 самых нагруженных эндпоинтов (отдельно по количетву запросов, отдельно — по затраченному машинному времени). 4 сигнала заменяют кучу производных метрик и позволяют однозначно сказать, лежит ли прод:
Чётко видна авария с 16:00 до 18:00
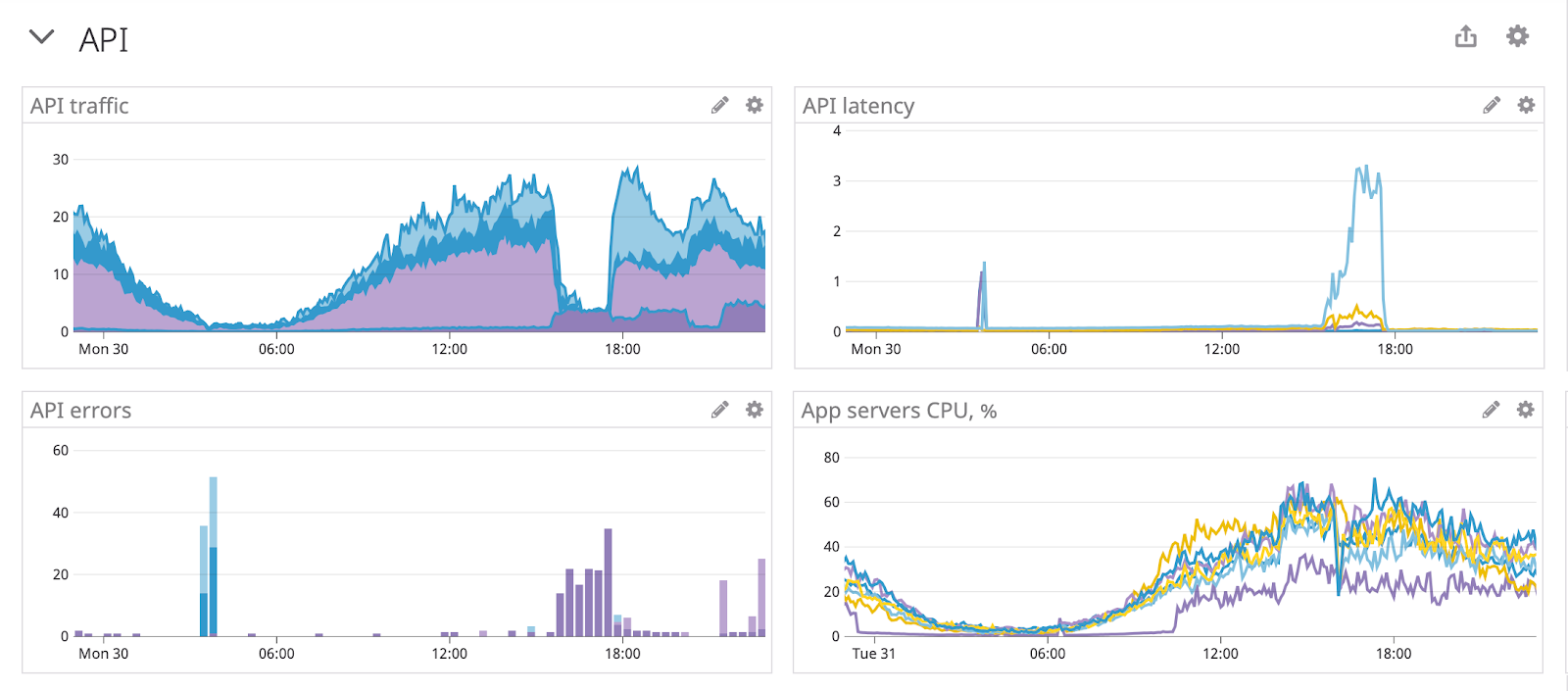
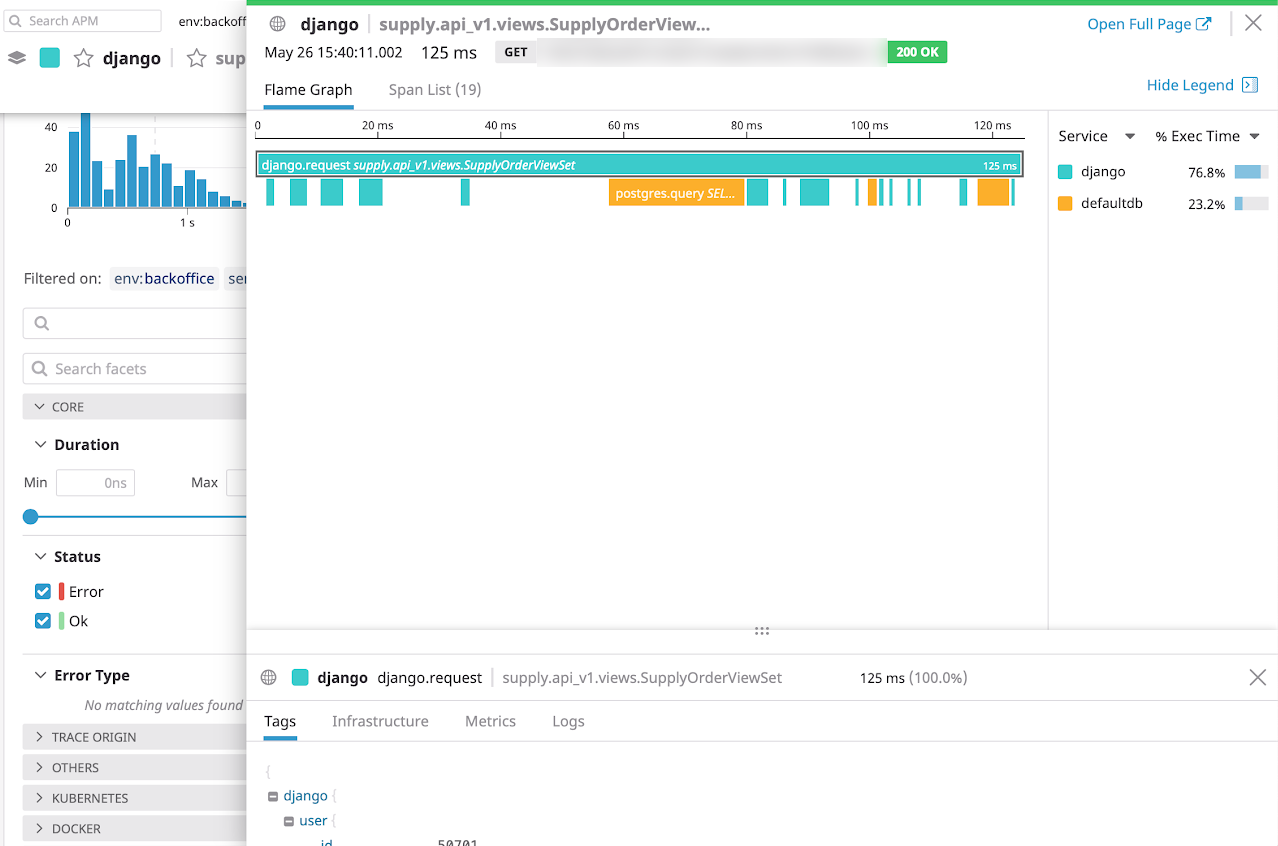
ТОП-10 запросов декомпозирует проблему из «упал прод» в «у нас тормозит эндпоинт деталей товара». Теперь легко локализовать источник — если увеличилось количество запросов, то ищем, того, кто их делает. Если запросов столько же, а нагрузка выросла — ищем, что поменялось в коде, или какие проблемы у нас могут быть на внешних ресурсах: базе данных, кеше или партнёрских API. Во втором случае здорово помогает разобрать поток выполнения — у каждого запроса, который обработал сервер, мы записываем трейс, в котором видно, сколько времени приложение потратило на каждую активность, а затем визуализируем это примерно вот так:
Flame graph показывает, что PostgreSQL отвечал чуть меньше, чем 30мс: отличный результат
Такая работа с цифрами и статистикой называется APM — App Performance Management. Мой любимый сервис для APM — Datadog. Я выбрал его когда-то за хороший дизайн: Datadog не просто даёт инструменты, которые собирают цифры, но и подсвечивает и объясняет самые важные из них.
Дефолтный борд Датадога для PostgreSQL
Если у вас есть хоть какой-то продакшн, который до сих пор не обложен цифрами — прикрутите к нему APM. Не хотите Датадог — есть куча конкурентов: New Relic, AppDynamics, AppOptics, Elastic APM.
Я плохо отношусь к людям, которые утверждают, что работают ночами. Если в своей команде вижу ночные коммиты — прихожу выяснять, что случилось.
Сколько бы мы ни посмотрели фильмов про хакеров и как бы романтично ни выглядела работа за двумя мониторами под покровом ночи, гигиену труда никто не отменял. Любому человеку нужно регулярно спать. Кому-то — 6, кому-то — 8 или даже 10 часов. Почитайте «Здоровый сон», если не верите.
Если разработчик нарушает это правило — значит, он у кого-то крадёт время. Либо у себя и своих близких (к примеру, сидит как овощ на семейных завтраках или вообще на них не ходит), либо у меня — тем, что за час пишет столько кода, сколько в рабочем состоянии написал бы за 10 минут.