Зачем и как начинать проекты на Django
Этот доклад я рассказывал в 2021 году, но в 2023 всё ещё ничего не изменилось: Django — по-прежнему лучший инструмент для веб-бекенда в Python, если не пытаться тащить в неё батарейки и генерить на ней HTML.
Фёдор Борщёв
Этот доклад я рассказывал в 2021 году, но в 2023 всё ещё ничего не изменилось: Django — по-прежнему лучший инструмент для веб-бекенда в Python, если не пытаться тащить в неё батарейки и генерить на ней HTML.
Update: мой бот постепенно закрывается. Рекомендую заменить его на @DeFensy_bot.
Комменты в телеге — отличный инструмент для дискуссий: не надо вводить почту и заполнять капчу; написать коммент так же легко как написать другу в другу; при желании легко перейти в личку. К сожалению, этой простотой пользуются спамеры — регистрируют аккаунты на левые симки и шлют GPT-сообщения о распродажах на вайлдберис, шокирующем выступлении Путина и даже о Ванге:
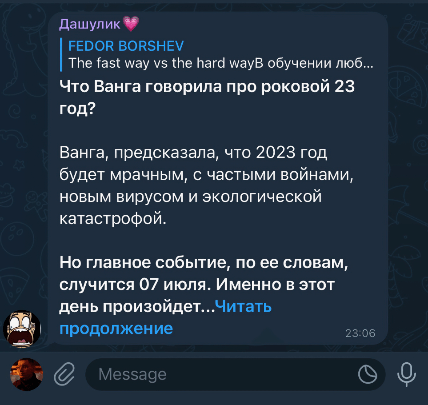
Telegram пока не борется с таким спамом — они нормально защищают чаты, но полностью игнорируют комменты каналов. И пока Дуров не завёз нам нормальный антиспам, я сделал это сам — запилил бота, который удаляет комменты спамеров.
Борьба со спамерами — это гонка вооружений: админы придумывают новый способ отличить нормальных людей от спамеров, спамеры придумывают как этот способ обойти, и так повторяется до бесконечности. При этом админы должны не слишком досаждать проверками обычным пользователям — если заставить людей заполнять капчу или подтверждать почту, то они просто перестанут писать.
Я очень не хочу вступать в эту гонку, поэтому предлагаю просто удалять из комментариев все виды ссылок — на сайты, чаты, каналы и даже на людей. Сообщение спамера без ссылки не имеет никакого смысла — по нему гарантированно никто не перейдёт. Конечно, живые люди тоже хотят обмениваться ссылками — им, к сожалению, придётся обойтись без этого, либо написать хотя бы несколько нормальных сообщений в чат, чтобы бот увидел, что они живые люди.
Я достаточно давно использую этого бота у себя в канале, и сейчас открыл его для всех. Чтобы запустить бота у себя, нужно просто добавить @discussion_sentinel_bot как админа в дискуссионную группу канала, разрешив ему удалять сообщения. Бот не поможет, если у вас не канал с комментариями, а чат. Вместо этого возьмите лучше daysandbox или shieldy.
Бот — бесплатный: не нужно подписываться ни на какие каналы, оплачивать подписку или читать чей-то спам. К сожалению, я не смогу даже написать вам, если изменю алгоритмы бота, но если вам зачем-то хочется следить за новостями — смотрите гитхаб.
Любое медиа существует для просмотров. Полная зависимость от трафика — это то, что объединяет Медузу и RT, ваш любимый канал с мемасами и редакцию Пивоварова, Википедию и сайты с гороскопами.
Весь контент всех медиа можно разделить на два вида — срочный и веченозелёный. Срочный контент — это новости, мемасы на злобу дня: в общем всё, что не будет иметь смысла через год-полтора. Вечнозелёный контент — это тексты\видео, польза которых не увядает со временем. Скорее всего любой медиасайт, который вы откроете, будет состоять из срочного контента, а большинство авторских блогов (как этот) — наоборот, вечнозелёные.
Срочный контент не несёт пользы — если не считать пользой ложную уверенность в том, что мы понимаем происходящее. Вечнозелёный контент, наоборот, более полезен — повышает кругозор, наводит на размышления. Срочный контент потреблять гораздо легче — если бы я писал пост не о том, как правильно потреблять медиа, о новом сенсационном заявлении американского президента, до этого места дочитало бы в два раза больше людей. Дело — в дофаминовой системе, если интересно, погуглите лекции Анны Обуховой.
Я почти всю жизнь обходился без срочного контента — просто не интересовался новостями. Это не было осознанным шагом — меня просто не цепляло. 2020 и 2022 годы довольно сильно поменяли мой формат потребления — начиная с обзоров политологов я к концу 2022 года скатился в чтение коммерсанта и даже периодически заходил на медузу. Осознав эту фигню, я осознанно взялся за формат потребления и наглухо заблокировал все медиа через /etc/hosts (тг-каналов, к счастью, у меня не было). Вот уже 4 месяца, как я не прочитал и не услышал ни одной единицы срочного контента.

В голове стало чище — появилось место для размышлений о будущем, осталось больше сил на личные проекты и игру на гитаре, я начал чаще писать в дневник. Думаю, это было лучшим решением как минимум за последние полгода.
Очень советую — заблокировать десяток сайтов и отписаться от кучки каналов вам почти ничего не стоит. Через пару недель пропадёт привычка хвататься за телефон, через месяц — почувствуете качественные изменения во внутреннем диалоге.
Недавно на Q&A «Есть минутки» мне задали вопрос — как вести асинхронную коммуникацию, когда периодически бывает, что сотрудник нужен срочно — упал тестовый стенд, ветка не мёрджится или просто нужно срочно сделать задачу.
Конечно, когда что-то действительно нужно срочно — никакая асинхронная коммуникация не сработает: надо писать, звонить и вообще разыскивать всеми доступными способами. Важно, что вы делаете в промежутках между такими авралами.
Большинство менеджеров почему-то воспринимают срочность как аксиому, типа «давайте сделаем чатик с сисадминами, потому что они бывают нам срочно нужны». Такое решение только маскирует проблему — они не анализируют причины проблемы, а лечат симптомы.

Работа менеджера\тимлида — не обслуживать срочность, создавая больше чатиков. Хороший менеджер, наоборот, убивает срочность — выделяет время, чтобы сделать неломаемые стенды; внедряет github flow, чтобы не было немёрджащихся веток; бьёт по рукам других менеджеров, которые выдумывают срочность, потому что не доверяют людям.
А если системно не работать над происходящим в компании, все будут друг-другу срочно нужны. Не обслуживайте срочность — убивайте её.
Одна из привычек, которая появилась у меня после 30 лет — не покупать ночные рейсы.
Идея ночных рейсов звучит довольно привлекательно: ты экономишь деньги, вылетая в 03:45, а аэропорт получает чуть более ровную загрузку. Но это же глупость! Во-первых, время — я, как дисциплинированный пассажир, приезжаю в аэропорт за два часа до вылета. Днём я трачу свободное время в аэропорте на работу — просто открываю ноутбук и делаю накопившиеся дела. В час ночи, я так сделать, увы, не могу — голова не работает.
Во-вторых — цель поездки. После ночного перелёта всё, что хочет нормальный человек — это отоспаться. Получается, что если я лечу в отпуск, то отпуск должен быть на один день больше. Если лечу по делам — дела занимают на один «отсыпной» день больше. А мог бы потратить этот день на что-нибудь полезное — хорошо отдохнуть и поработать.

Вряд ли разница в стоимости билетов (пусть она будет хоть 30%) стоит больше, чем деньги, которые я могу заработать за счёт того, что не перехожу в состояние сонной коровы.