Когда мне выпадает возможность взять новую и сложную активность вроде нового клиента или нового проекта, я пытаюсь понять: насколько я вообще хочу этим заниматься.
В какой-то момент таких активностей стало настолько много, что я в них погряз — просто брал всё, что казалось интересным и перегружался. В итоге не делал ничего важного, фокусируясь только на срочных делах, не делать которые было невозможно.
Сейчас, каждый раз, когда нужно принять решение, я провожу простой мысленный эксперимент: «Готов ли я этим заниматься всю жизнь?».
— Готов ли я всю жизнь писать код для клиента, чья доменная область у меня вызывает отвращение? Ну тогда и начинать не стоит.
— Готов ли я всю жизнь делать проект, который не принесёт денег или морального удовлетворения? Нет.
— Готов ли я всю жизнь вести бизнес, который никогда не смасштабируется? Вряд ли.
Возможно метод работает потому, что вся жизнь — это настолько серьёзный коммитмент, что мозг выключается из ежедневной тупой рутины и начинает думать глобальнее. Может ещё почему-нибудь, не знаю. Но пустых и неважных проектов у меня стало гораздо меньше.
Недавно мы закончили важную веху — запустили новый движок блогов на snob.ru. Задача была нетривиальной — за полгода мы перезапустили сайт высоконагруженного медиа с кучей легаси-кода. В этой заметке я расскажу, какие технологические решения мы приняли.
Задача
Сноб — это интернет-медиа, статьи в котором пишут не только штатные редакторы, но и внешние участники проекта: любой человек может приобрести подписку и завести собственную колонку на snob.ru. Коду проекта больше 10 лет, писали его разные люди на совершенно разных технологиях — в копилке есть и Zend Framework с MySQL и Django с PostgreSQL.
Нас с Саматом позвали, когда разработка была в плачевном состоянии: новые фичи уже не выкатывали, а починка одного бага приводила к появлению двух-трёх новых. Первым делом мы провели аудит: поговорили с представителями бизнеса и программистами, расковыряли исходный код и инфраструктуру. Проблемы оказались буквально везде: программисты были уставшими, инфраструктура — непрозрачной, а техдолг — огромным. Остановимся на техдолге чуть-чуть подробнее.
Проект состоит не из одного бэкенда, а из трёх: основной сайт, блоги внешних участников проекта и редакционная админка. Архитектуру взаимодействия никто не продумывал — каждую новую систему городили на предыдущие как придётся. Это привело к тому, что данные между бекендами стали передаваться совершенно непредсказуемым образом: частично через запись в базу, частично — через вебхуки. Из-за этого пользователи периодически теряют данные: если материал, профиль или комментарий не укладывается в формат обмена между системами (или в момент сохранения пролетает птичка и моргает сеть) — данные портятся.
Кроме трёх бэкендов, у проекта есть ещё три фронтенда: старый от ПХП-движка, куча кода на Django и SPA на next.js, от которого предыдущая команда успела внедрить совсем небольшие части функциональности. Сверху всего этого стоит nginx, который одним ему ведомым образом решает, какая из этих систем будет отрабатывать запрос.
Старая версия блогов. Обратите внимание на форму входа в верхнем левом углу — переписать и сделать её приятной почти невозможно.
Поговорив с бизнесом, мы поняли, что самая большая проблема — в ПХП-движке на Zend Framework, который обслуживает блоги участников проекта. У бизнеса есть куча гипотез, которые можно проверить, но ни одного ПХП-шинка в команде не осталось, а внешних нанять невозможно — ни один нормальный программист не пойдет работать на 10-летний легаси без здоровой инженерной культуры.
Решение
Конечно, работать дальше с таким легаси нельзя — надо как можно скорее от него избавляться. Поскольку бизнес больше всего хотел решить проблему с блогами — с них мы и начнём. Мы поставили амбициозную цель — в конце работы оставить движок, которым пользуются и блогеры, и редакция: такое уже есть у Комитета, на их «Основе» работают все сайты издательства: vc, tjournal, dtf, и редакция там пишет посты так же, как и обычные пользователи.
Архитектура: однонаправленный поток данных
Решение мы начали с разработки архитектуры. В реальном мире существует только одно состояние у поста, комментария или пользователя — то, которое мы видим на экране. Проблема старой архитектуры в том, из-за ошибок проектирования это состояние в разных версиях размазано между совершенно несвязанными базами данных, и записывают его неаккуратные и несогласованные друг с другом системы. Представьте себе текст на листе бумаги, который одновременно пишут четыре первоклассника. Даже если они договорятся писать по одному слову за раз и вместе напишут связанный текст — вы никогда не поймёте, кто из них пропустил запятую или допустил смысловую ошибку.
Чтобы всегда знать, кто, зачем и когда записал данные, мы ввели единый источник правды. Пусть правдивое состояние пользователей и постов всегда находится у нас, и мы сами отвечаем за то, чтобы данные обновились в легаси-системах — транслируем все изменения в базы данных, задействуя как можно меньше старого кода. Всю синхронизацию систем друг с другом мы отрубаем — данные везде пишем только мы. Получается, что правда течёт сверху вниз, как в компонентах react.js — от нашей системы к легаси.
Экспорт данных мы построили на celery и RabbitMQ. Получилась полноценная асинхронная архитектура: все посты, которые нужно отправить в легаси, лежат в RabbitMQ, и удаляются оттуда только после того, как данные попадают во все БД. Если с трансляцией что-то пойдёт не так — мы узнаем об этом по переполненной очереди в RabbitMQ.
Инфраструктура
Инфраструктура на проекте — ещё один источник проблем. Там были разные физические серверы, конфигурация которых мутировала в течении десятилетия. ПХП-движок вообще крутился на FreeBSD — такой привет из начала 2000х! Плюс, у нас не было доступа к серверам — нельзя было даже зайти по ssh и посмотреть, что происходит.
Конечно, мы совсем не хотели делать ещё одну систему в этой непрозрачной мешанине — пара недель ушла бы только на попытки разобраться в конфигурации nginx. Решение пришло из мира фронтенда: там часто делают отдельный бекенд для фронтендеров, который который облегчает хождение в основные бекенды — маршрутизирует запросы между микросервисами, переформатирует ответы в удобный фронтенду формат, сохраняет данные авторизации — это называется BFF (Backend for Frontend). В нашем проекте уже был свой BFF — ведь нам нужно рендерить страницы на сервере, чтобы ускорить загрузку и быть понятными для поисковых роботов. Нам ничего не мешает маршрутизировать весь трафик snob.ru, включая статику через свой BFF — таким образом мы заберём полный контроль над трафиком.
Рядом с легаси-инфраструктурой мы развернули свою собственную, где на входе пользователей встречает комбинация из traefik и express.js. Теперь мы сами решаем, какая из систем обрабатывает каждый запрос — каждый новый сервис сам регистрируется в traefik и получает свою долю трафика. Если ни один сервис не хочет обрабатывать запрос — он уходит в express.js, где мы кодом решаем, обработать сервис своим фронтендом, или отдать его в легаси.
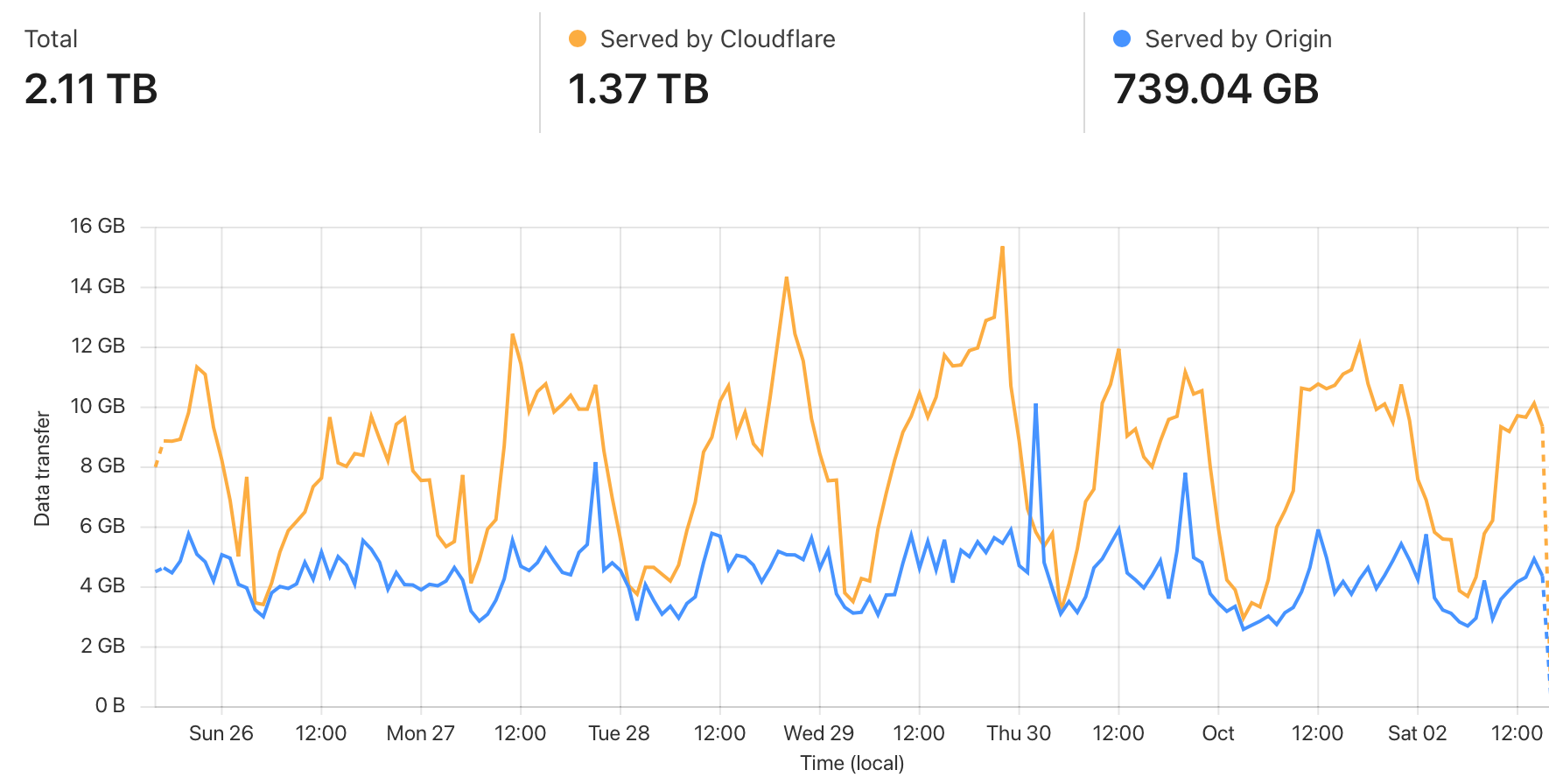
Чтобы не надорваться от нагрузки, поверх подключили Cloudflare, который раздаёт статику через свой CDN:
2/3 легаси-трафика отдаётся через CDN
Заодно мы решили ещё одну проблему старой инфраструктуры — пропуская через себя весь трафик, мы наконец-то получили нормальную статистику происходящего в ней. Старый мониторинг строился на основе простой пинговалки в заббиксе: раз в минуту ходим в бекенд, если ответ не ок — шлём СМС админу. Чтобы понять, насколько это плохо — представьте ситуацию, в которой сайт падает от нагрузки и нормально обрабатывает только 50% пользователей. Если пинговалка попадает в ту половину пользователей, для которых сайт работает — админ об этом никогда не узнает. Наверное так же можно проверять работу ядерного реактора — если в контейнменте ничего не горит и не взрывается, значит реактор работает.
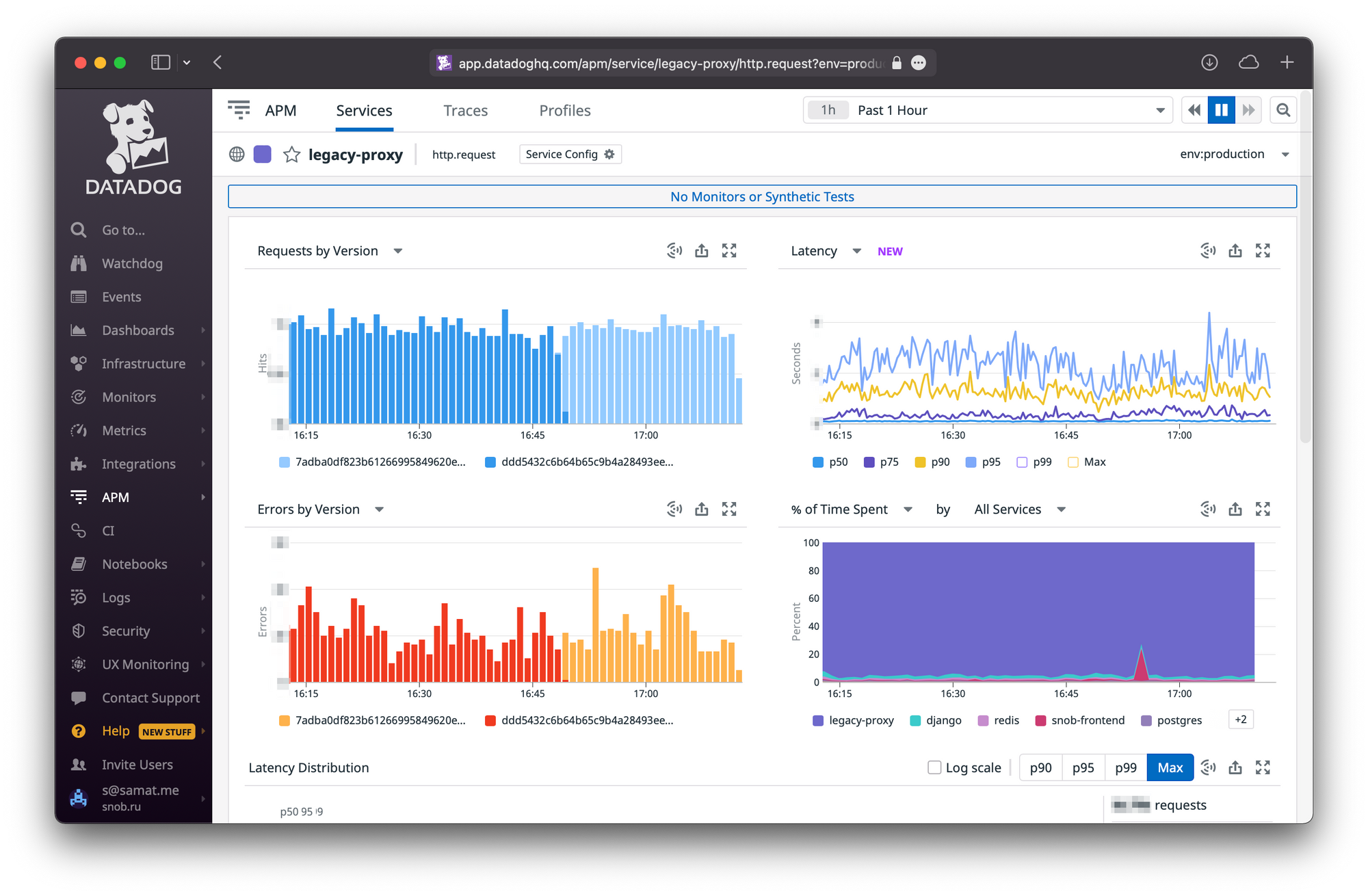
Теперь никакой пинговалки нет, а мониторинг строится на 4-х золотых сигналах — количестве запросов, времени ответа, количестве ошибок и запасу на оборудовании.
Графики 4 золотых сигналов в Datadog, в которую мы завели весь мониторинг
Если хоть какой-то параметр выходит из строя, робот на основе машинного обучения шлёт нам алёрт.
Так выглядит алёрт в Campfire — чате внутри нашего корпоративного бейскемпа
Как мы тестировали легаси
Закрытая инфраструктура создала нам ещё одну проблему — мы не могли собрать тестовые стенды. В старом коде в неподдающемся учёту количестве мест были захардкожены адреса и пароли продакшена — то есть даже если развернуть систему на машине разработчика, никто не может быть уверен, что локальный экземпляр не запишет что-нибудь в боевую базу.
Получается, что как ни пиши автотесты в нашем коде, мы не можем быть уверены в качестве системы в целом — не существует никакого способа проверить, что когда мы выкатимся на продакшен, ничего не упадёт.
Единственный подход к тестированию, который применим в данном случае — канареечный: когда мы выкатываем всю систему в прод, но показываем её минимальному количеству пользователей. Примерно за три месяца до запуска у нас в продакшене появилась рабочая система — через новый интерфейс можно было написать пост, который появился бы во сразу всех базах. При желании можно было даже вывести этот пост на главную страницу snob.ru! Конечно, система была непроработанной — сначала можно было написать только заголовок и текст, указать автора: ни о каком сложном форматировании речи не шло.
Новая система была в продакшене за два месяца до дедлайна — это дало нам достаточно времени, чтобы решить все возможные интеграционные проблемы.
Запуск
Несмотря на то, что к дедлайну система была уже в продакшене, оставались самые опасные вещи — переписать DNS и включить боевой стриминг данных реальных пользователей. Опасность была в том, что старая система в совершенно непредсказуемых местах ходила сама в себя (помните вебхуки?). В коде были конструкции вида urlopen('<http://snob.ru/secret_api/secret_endpoint>');! Большая часть этих адресов оставалась работоспособной — почти весь трафик мы перенаправляли в легаси, обрабатывая самостоятельно только нужную нам часть. Но какие-то легаси-адреса всё равно сломалась — к примеру перестал работать старый механизм загрузки фотографий.
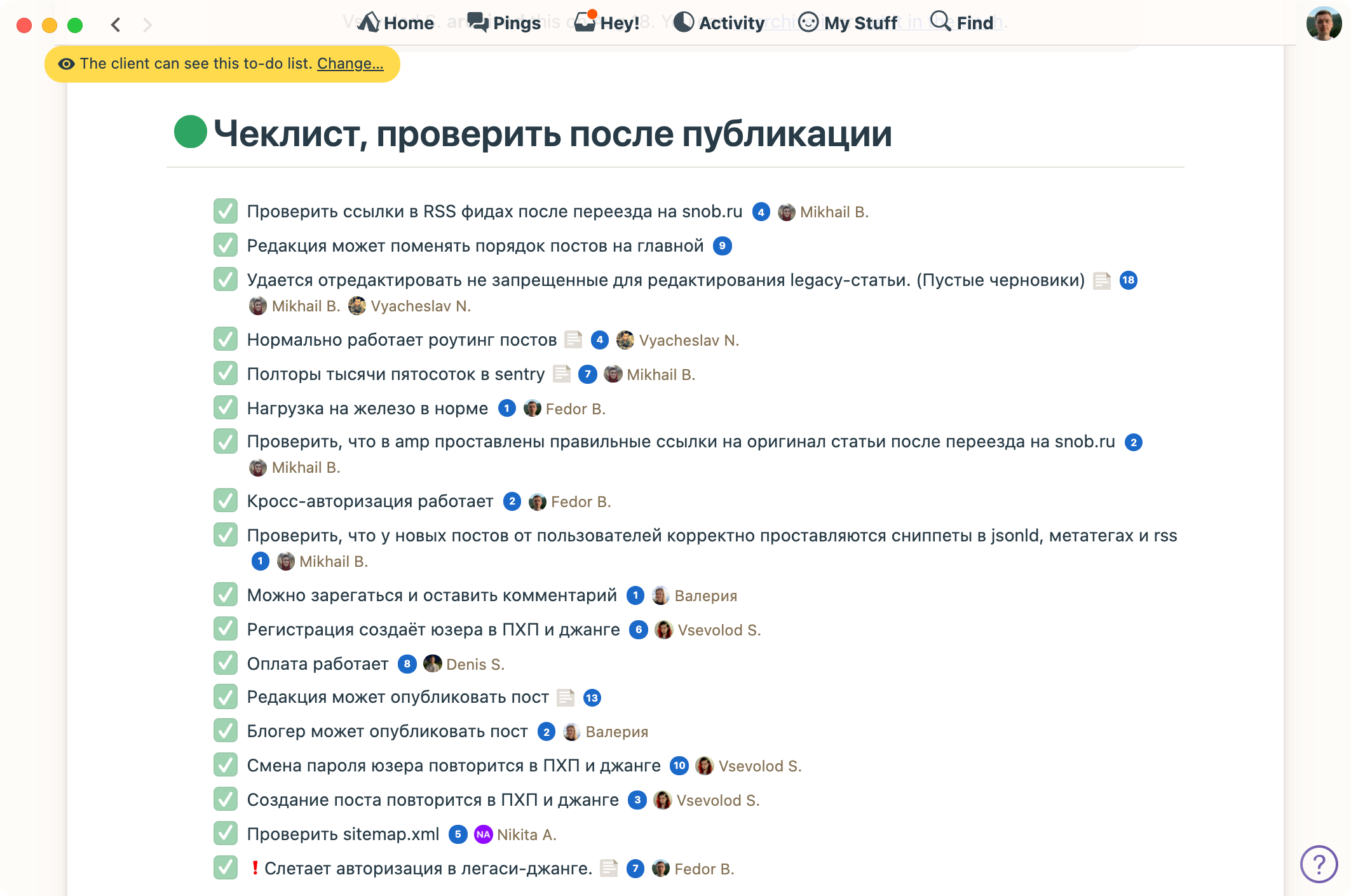
Поскольку, не переписывая DNS, мы не могли этого проверить — оставалось тестировать всё на боевой системе. Для этого мы собрали процесс, который позволяет быстро переключить трафик со старого кода на новый и обратно. Чтобы включить новый прод, достаточно было поменять адрес в Cloudflare и раскатать плейбук Ansible с обновлёнными настройками — весь процесс занимал около трёх минут. Чтобы ничего не забыть, сделали простой чеклист в бейскемпе:
Кусок чеклиста, которым мы проверяли продакшен-запуск
Всего мы сделали четыре тестовых запуска, все были в будни и без потери трафика. Не буду останавливаться подробно на всех проблемах, которые мы выловили в ходе тестирования — большая часть решалась тем, чтобы поправить очередную захардкоженную строку в легаси.
Что дальше
Сейчас у нас есть движок, в котором решены все проблемы интеграции, а код и основные пользовательские сценарии покрыты тестами. Остаётся потихоньку забирать функциональность у легаси-кода и тушить старые части системы, переводя весь snob.ru на новые рельсы. До встречи через полгода :-)
Команда
Никита Алёшников, бэкенд-разработчик Фёдор Борщёв, технический директор Михаил Бурмистров, ведущий фронтенд-разработчик Самат Галимов, технический директор Вячеслав Набатчиков, бэкенд-разработчик Всеволод Скрипник, бэкенд-разработчик, руководитель проекта Денис Сурков, бэкенд-разработчик Владимир Тарановский, фронтенд-разработчик
Наш дорогой заказчик:
Марина Геворкян, генеральный директор Валерия Тищенко, бренд-директор, продакт Артём Алексеев, дизайнер Мария Семенюк, директор по маркетингу Виктория Владимирова, директор по дистрибуции Борис Тавакалов, ведущий разработчик и хранитель знаний legacy-системы Михаил Лавкин, системный администратор legacy-системы Данияр Шекебаев, аналитик Александр Тарасов, техподдержка
Во всех коллективах, где я работал, самой большой ценностью для меня было услышать эту фразу. Не пассивное неодобрение, не мягкую критику, а именно «ты сделал говно». Неважно — про код, тексты, письма клиентам или результаты переговоров.
«Ты сделал говно» — это же самая обычная обратная связь. Когда коллектив видит говно, но не кричит о нём, его участники как бы соглашаются: да, у нас можно делать говно, и мы никого не будем учить делать неговно, пусть сами разбираются.
Представьте, если первоклассник принёс учителю решение, что 2 x 2 = 3, а учитель в ответ выражает просто мягкое неодобрение, но не говорит, что правильно будет 4? Математика никогда не откроется ребёнку как точная наука, скорее ощущение будет «ну, я что-то делаю, что-то, наверное, получается».
Когда я нанимаю людей, при первом же удобном случае провожу их через ситуацию «ты сделал говно»: ловлю на ошибке и подробно и спокойно разбираю её. Если новый сотрудник воспринимает такой разбор с благодарностью, значит, наши ценности совпадают и мы, скорее всего, сработаемся. Если злится, закрывается или доказывает мне, что никакой ошибки на самом деле не было, — вряд ли.
Важно — именно «ты сделал говно», а не «ты — мудак». Критиковать можно только работу, но не личность.
Всю активность менеджера можно условно разделить на два вида: реагирование и инициирование. Реагирование — это работа с внешними раздражителями: телефонными звонками, письмами, коллегами, которые подошли с вопросом.
Инициирование — это действия, направленные на то, чтобы результаты достигались, а раздражителей было поменьше: планирование встреч, отчеты, постановка задач.
Плохой менеджер всегда больше реагирует, чем инициирует. Вместо того, чтобы тратить по 10 минут в неделю на регулярное отчетное письмо команде, он предпочитает лично в слаке рассказывать каждому новости, и потом ещё решать проблемы вызванные дискоммуникацией, когда левая рука не знает, что делает правая.
У программистов все так же: плохой программист реагирует на инциденты вроде упавшего прода, а хороший — делает так, чтобы прод не падал: пишет тесты, внимательно проверяет работу перед публикацией, настраивает автооткат проблемных изменений, строит процессы и коммуникацию вокруг себя.
Чем больше вы инициируете, тем меньше становится раздражителей, на которые приходится реагировать, а значит тем спокойнее вы спите и тем лучше управляете своим расписанием.
Хороший менеджер задаёт этот вопрос во время каждой своей активности.
Какую ценность я добавил, когда сходил на встречу? Был ли полезен, принёс что-то новое или тупил в фейсбук?
Какую ценность я добавил, когда ответил на письмо? Легче ли стало совершить следующий шаг по проекту?
Какую ценность я добавил, когда поговорил с программистом? Стало ли ему понятнее, что и как делать на проекте?
Какую ценность я добавил за неделю руководства отделом? А за месяц?
Если нечего ответить, значит пора переставать заниматься деятельностью, которая не приносит ценности: отказаться от встреч с командой, которой ты не нужен, не слать пустые отписки на письма, не отвлекать программистов. Или просто отдохнуть.